



Basic code settings
#!pip install python-dotenv #!pip install openai import os import openai from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] def get_completion(prompt, model="gpt-3.5-turbo"): messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0, ) return response.choices[0].message["content"]
Models, Prompts and Parsers
Why use prompt templates?
- Prompts can be long and detailed.
- Reuse good prompts when you can!
- LangChain also provides prompts for common operations.
Code
from langchain.output_parsers import ResponseSchema from langchain.output_parsers import StructuredOutputParser gift_schema = ResponseSchema(name="gift", description="Was the item purchased\ as a gift for someone else? \ Answer True if yes,\ False if not or unknown.") delivery_days_schema = ResponseSchema(name="delivery_days", description="How many days\ did it take for the product\ to arrive? If this \ information is not found,\ output -1.") price_value_schema = ResponseSchema(name="price_value", description="Extract any\ sentences about the value or \ price, and output them as a \ comma separated Python list.") response_schemas = [gift_schema, delivery_days_schema, price_value_schema] output_parser = StructuredOutputParser.from_response_schemas(response_schemas) format_instructions = output_parser.get_format_instructions() print(format_instructions) review_template_2 = """\ For the following text, extract the following information: gift: Was the item purchased as a gift for someone else? \ Answer True if yes, False if not or unknown. delivery_days: How many days did it take for the product\ to arrive? If this information is not found, output -1. price_value: Extract any sentences about the value or price,\ and output them as a comma separated Python list. text: {text} {format_instructions} """ prompt = ChatPromptTemplate.from_template(template=review_template_2) messages = prompt.format_messages(text=customer_review, format_instructions=format_instructions) print(messages[0].content) response = chat(messages) print(response.content) output_dict = output_parser.parse(response.content) output_dict.get('delivery_days')
Memory


Memory Types
- ConversationBufferMemory: This memory allows storing messages and then extracts the messages in a variable.
- ConversationBufferWindowMemory: This memory keeps a list of the interactions of the conversation over time. It only uses the last K interactions.
- ConversationTokenBufferMemory: This memory keeps a buffer of recent interactions in memory and uses token length rather than number of interactions to determine when to flush interactions.
- ConversationSummaryMemory: This memory creates a summary of the conversation over time. → This is pretty useful for long conversations.
Additional Memory types
- Vector data memory : Stores text (from conversation or elsewhere) in a vector database and retrieves the most relevant blocks of text.
- Entity memories : Using an LLM, it remembers details about specific entities.
You can also use multiple memories at one time.
E.g., Conversation memory + Entity memory to recall individuals.
You can also store the conversation in a conventional database (such as key-value store or SQL)
ConversationBufferMemory
Notebook code
import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file import warnings warnings.filterwarnings('ignore') from langchain.chat_models import ChatOpenAI from langchain.chains import ConversationChain from langchain.memory import ConversationBufferMemory llm = ChatOpenAI(temperature=0.0) memory = ConversationBufferMemory() conversation = ConversationChain( llm=llm, memory = memory, verbose=False ) conversation.predict(input="Hi, my name is Andrew") conversation.predict(input="What is 1+1?") conversation.predict(input="What is my name?") print(memory.buffer) """ Human: Hi, my name is Andrew AI: Hello Andrew, it's nice to meet you. My name is AI. How can I assist you today? Human: What is 1+1? AI: The answer to 1+1 is 2. Human: What is my name? AI: Your name is Andrew, as you mentioned earlier. """ memory.load_memory_variables({}) memory = ConversationBufferMemory() # This resets the memory memory.save_context({"input": "Hi"}, {"output": "What's up"}) print(memory.buffer) memory.load_memory_variables({}) # We will be additing additional context to the memory memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool"}) memory.load_memory_variables({})
- As the conversation goes on the memory context size increases.
ConversationBufferWindowMemory
- Here we can set the latest recent k number of conversations to store.
Notebook Code
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1) memory.save_context({"input": "Hi"}, {"output": "What's up"}) memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool"}) memory.load_memory_variables({}) llm = ChatOpenAI(temperature=0.0) memory = ConversationBufferWindowMemory(k=1) # k is the number of previous conversation iterations conversation = ConversationChain( llm=llm, memory = memory, verbose=False ) conversation.predict(input="Hi, my name is Andrew") conversation.predict(input="What is 1+1?") conversation.predict(input="What is my name?")
ConversationTokenBufferMemory
- Here we can set the maximum tokens which can be stored.
Notebook Code
#!pip install tiktoken from langchain.memory import ConversationTokenBufferMemory from langchain.llms import OpenAI llm = ChatOpenAI(temperature=0.0) memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=30) memory.save_context({"input": "AI is what?!"}, {"output": "Amazing!"}) memory.save_context({"input": "Backpropagation is what?"}, {"output": "Beautiful!"}) memory.save_context({"input": "Chatbots are what?"}, {"output": "Charming!"}) memory.load_memory_variables({})
ConversationSummaryBufferMemory
- Instead of the above two limits like tokens and conversations on actual conversations, this method stores a summary of the last conversations and stores those as context with a high token limit.
Notebook Code
from langchain.memory import ConversationSummaryBufferMemory # create a long string schedule = "There is a meeting at 8am with your product team. \ You will need your powerpoint presentation prepared. \ 9am-12pm have time to work on your LangChain \ project which will go quickly because Langchain is such a powerful tool. \ At Noon, lunch at the italian resturant with a customer who is driving \ from over an hour away to meet you to understand the latest in AI. \ Be sure to bring your laptop to show the latest LLM demo." memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=100) memory.save_context({"input": "Hello"}, {"output": "What's up"}) memory.save_context({"input": "Not much, just hanging"}, {"output": "Cool"}) memory.save_context({"input": "What is on the schedule today?"}, {"output": f"{schedule}"}) memory.load_memory_variables({}) conversation = ConversationChain( llm=llm, memory = memory, verbose=True ) conversation.predict(input="What would be a good demo to show?") memory.load_memory_variables({})
Chains
- Chains are the basic fundamental unit in Langchain. That’s why the name has a chain, Langchain.
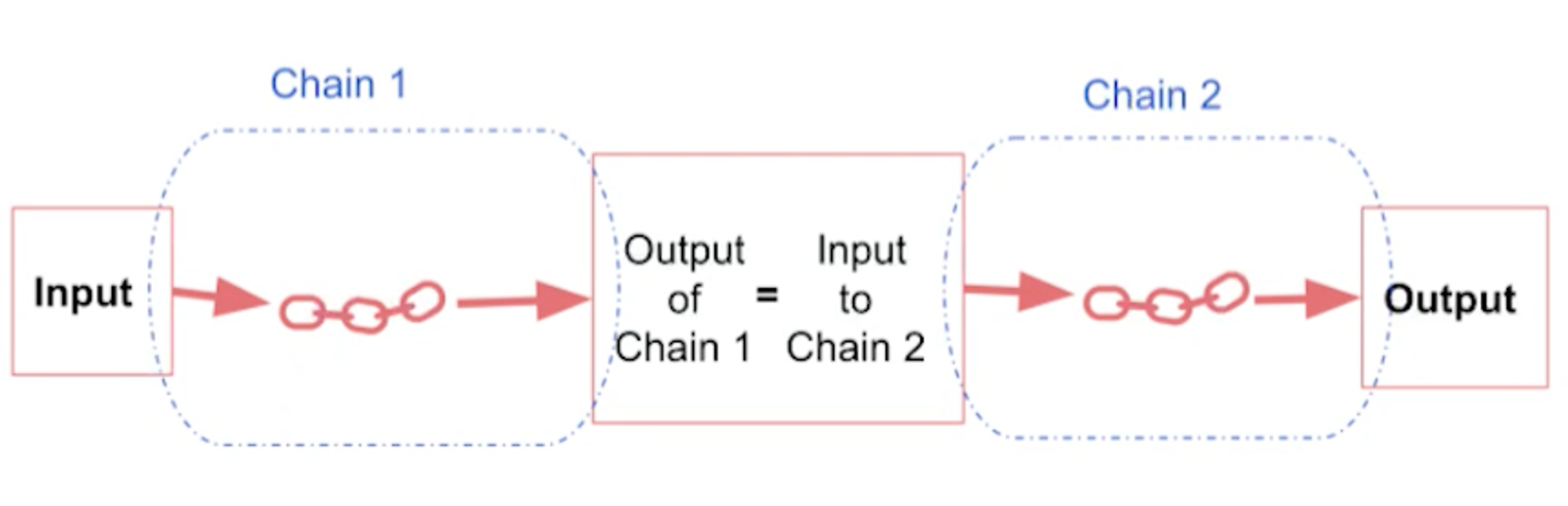
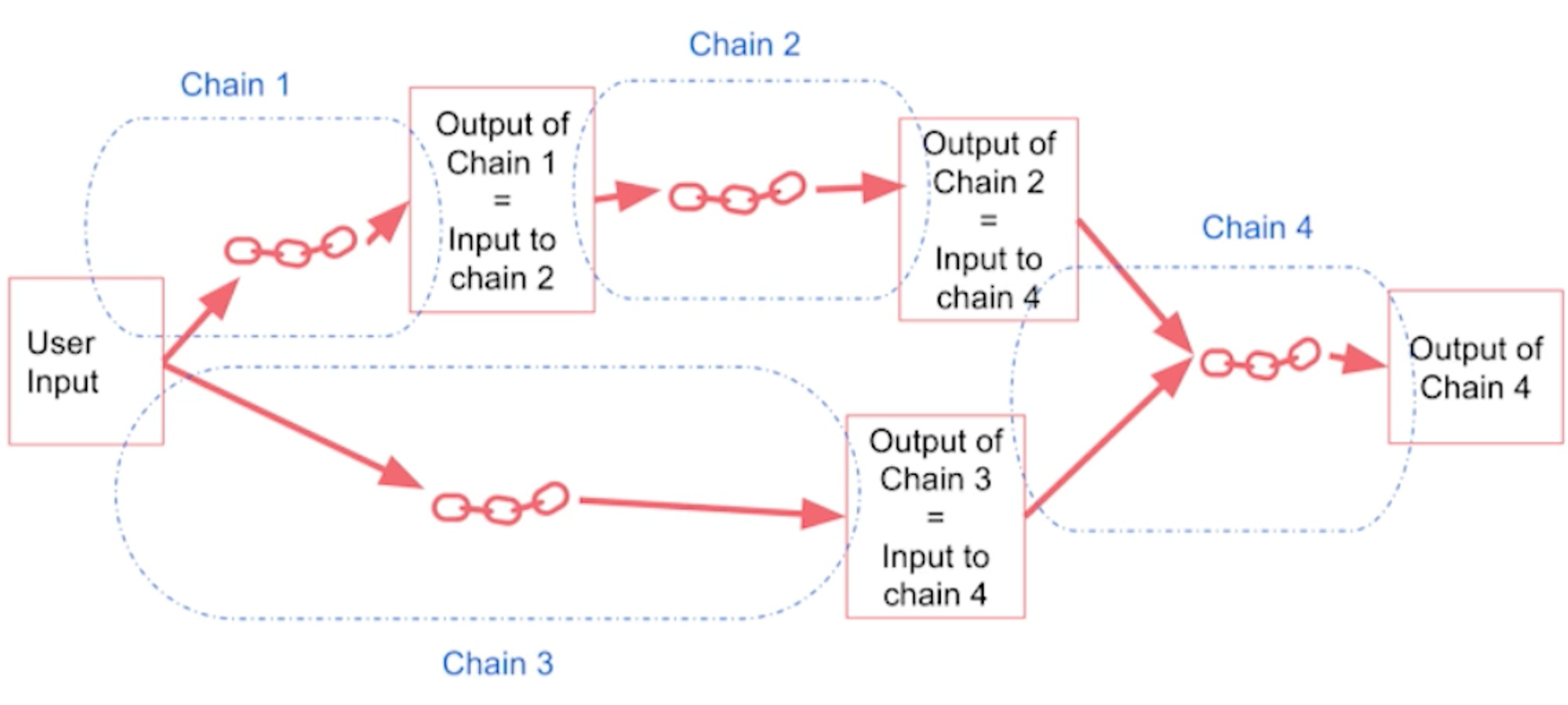
- A sequential chain is another type of chain. The idea is to combine multiple chains where one chain's output is the next chain's input.
- A sequential chain is another type of chain. The idea is to combine multiple chains where one chain's output is the next chain's input.
- There is two types of sequential chains:
- SimpleSequentialChain: Single input/output
- SequentialChain: multiple inputs/outputs

Notebook Code
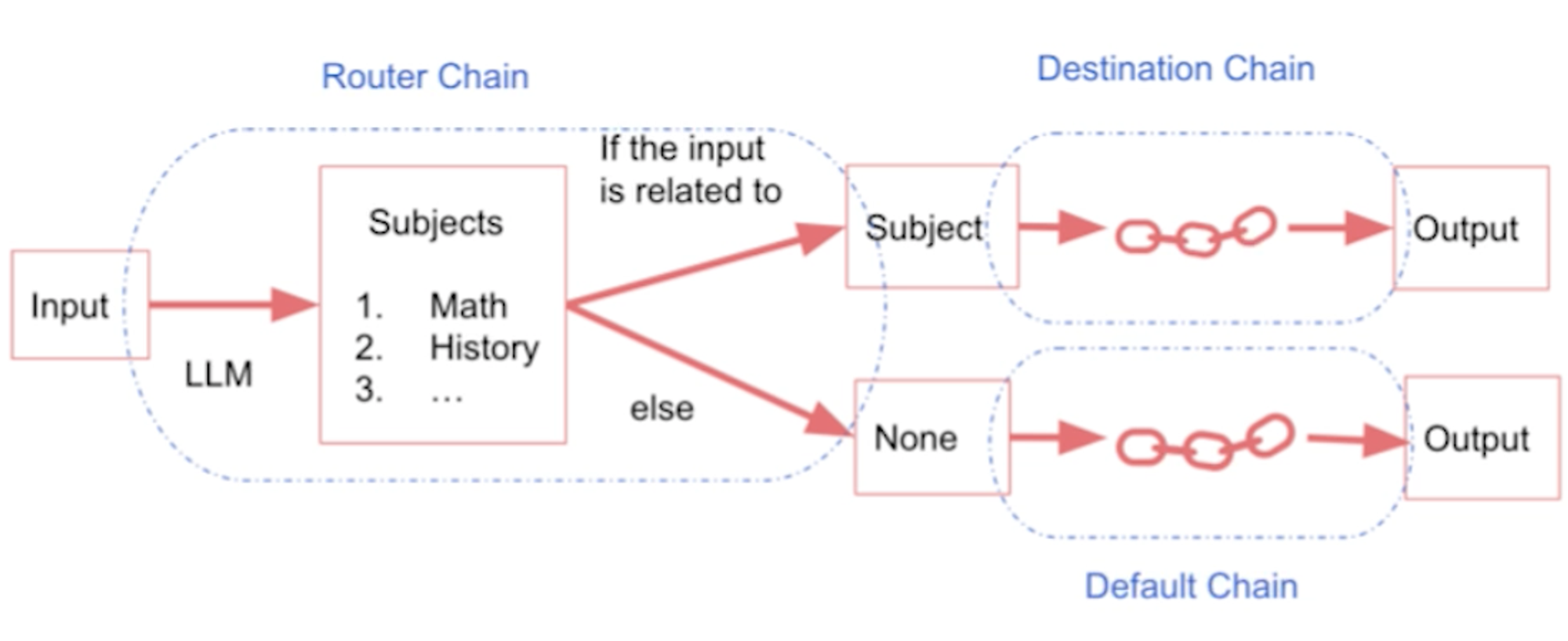
""" We will discuss the following: * LLMChain * Sequential Chains * SimpleSequentialChain * SequentialChain * Router Chain """ import warnings warnings.filterwarnings('ignore') import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file #!pip install pandas import pandas as pd df = pd.read_csv('Data.csv') df.head() # LLMChain from langchain.chat_models import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.chains import LLMChain llm = ChatOpenAI(temperature=0.9) prompt = ChatPromptTemplate.from_template( "What is the best name to describe \ a company that makes {product}?" ) chain = LLMChain(llm=llm, prompt=prompt) product = "Queen Size Sheet Set" chain.run(product) # SimpleSequentialChain from langchain.chains import SimpleSequentialChain llm = ChatOpenAI(temperature=0.9, model=llm_model) # prompt template 1 first_prompt = ChatPromptTemplate.from_template( "What is the best name to describe \ a company that makes {product}?" ) # Chain 1 chain_one = LLMChain(llm=llm, prompt=first_prompt) # prompt template 2 second_prompt = ChatPromptTemplate.from_template( "Write a 20 words description for the following \ company:{company_name}" ) # chain 2 chain_two = LLMChain(llm=llm, prompt=second_prompt) overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True ) overall_simple_chain.run(product) # SequentialChain from langchain.chains import SequentialChain llm = ChatOpenAI(temperature=0.9, model=llm_model) # prompt template 1: translate to english first_prompt = ChatPromptTemplate.from_template( "Translate the following review to english:" "\n\n{Review}" ) # chain 1: input= Review and output= English_Review chain_one = LLMChain(llm=llm, prompt=first_prompt, output_key="English_Review" ) second_prompt = ChatPromptTemplate.from_template( "Can you summarize the following review in 1 sentence:" "\n\n{English_Review}" ) # chain 2: input= English_Review and output= summary chain_two = LLMChain(llm=llm, prompt=second_prompt, output_key="summary" ) # prompt template 3: translate to english third_prompt = ChatPromptTemplate.from_template( "What language is the following review:\n\n{Review}" ) # chain 3: input= Review and output= language chain_three = LLMChain(llm=llm, prompt=third_prompt, output_key="language" ) # prompt template 4: follow up message fourth_prompt = ChatPromptTemplate.from_template( "Write a follow up response to the following " "summary in the specified language:" "\n\nSummary: {summary}\n\nLanguage: {language}" ) # chain 4: input= summary, language and output= followup_message chain_four = LLMChain(llm=llm, prompt=fourth_prompt, output_key="followup_message" ) # overall_chain: input= Review # and output= English_Review,summary, followup_message overall_chain = SequentialChain( chains=[chain_one, chain_two, chain_three, chain_four], input_variables=["Review"], output_variables=["English_Review", "summary","followup_message"], verbose=True ) review = df.Review[5] overall_chain(review) # Router Chain physics_template = """You are a very smart physics professor. \ You are great at answering questions about physics in a concise\ and easy to understand manner. \ When you don't know the answer to a question you admit\ that you don't know. Here is a question: {input}""" math_template = """You are a very good mathematician. \ You are great at answering math questions. \ You are so good because you are able to break down \ hard problems into their component parts, answer the component parts, and then put them together\ to answer the broader question. Here is a question: {input}""" history_template = """You are a very good historian. \ You have an excellent knowledge of and understanding of people,\ events and contexts from a range of historical periods. \ You have the ability to think, reflect, debate, discuss and \ evaluate the past. You have a respect for historical evidence\ and the ability to make use of it to support your explanations \ and judgements. Here is a question: {input}""" computerscience_template = """ You are a successful computer scientist.\ You have a passion for creativity, collaboration,\ forward-thinking, confidence, strong problem-solving capabilities,\ understanding of theories and algorithms, and excellent communication \ skills. You are great at answering coding questions. \ You are so good because you know how to solve a problem by \ describing the solution in imperative steps \ that a machine can easily interpret and you know how to \ choose a solution that has a good balance between \ time complexity and space complexity. Here is a question: {input}""" prompt_infos = [ { "name": "physics", "description": "Good for answering questions about physics", "prompt_template": physics_template }, { "name": "math", "description": "Good for answering math questions", "prompt_template": math_template }, { "name": "History", "description": "Good for answering history questions", "prompt_template": history_template }, { "name": "computer science", "description": "Good for answering computer science questions", "prompt_template": computerscience_template } ] from langchain.chains.router import MultiPromptChain from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser from langchain.prompts import PromptTemplate llm = ChatOpenAI(temperature=0, model=llm_model) destination_chains = {} for p_info in prompt_infos: name = p_info["name"] prompt_template = p_info["prompt_template"] prompt = ChatPromptTemplate.from_template(template=prompt_template) chain = LLMChain(llm=llm, prompt=prompt) destination_chains[name] = chain destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos] destinations_str = "\n".join(destinations) default_prompt = ChatPromptTemplate.from_template("{input}") default_chain = LLMChain(llm=llm, prompt=default_prompt) MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a \ language model select the model prompt best suited for the input. \ You will be given the names of the available prompts and a \ description of what the prompt is best suited for. \ You may also revise the original input if you think that revising\ it will ultimately lead to a better response from the language model. << FORMATTING >> Return a markdown code snippet with a JSON object formatted to look like: ```json {{{{ "destination": string \ name of the prompt to use or "DEFAULT" "next_inputs": string \ a potentially modified version of the original input }}}} ``` REMEMBER: "destination" MUST be one of the candidate prompt \ names specified below OR it can be "DEFAULT" if the input is not\ well suited for any of the candidate prompts. REMEMBER: "next_inputs" can just be the original input \ if you don't think any modifications are needed. << CANDIDATE PROMPTS >> {destinations} << INPUT >> {{input}} << OUTPUT (remember to include the ```json)>>""" router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format( destinations=destinations_str ) router_prompt = PromptTemplate( template=router_template, input_variables=["input"], output_parser=RouterOutputParser(), ) router_chain = LLMRouterChain.from_llm(llm, router_prompt) chain = MultiPromptChain(router_chain=router_chain, destination_chains=destination_chains, default_chain=default_chain, verbose=True ) chain.run("What is black body radiation?") chain.run("what is 2 + 2") chain.run("Why does every cell in our body contain DNA?")


Q&A
Notebook Code
#!/usr/bin/env python # coding: utf-8 # # LangChain: Q&A over Documents # # An example might be a tool that would allow you to query a product catalog for items of interest.#pip install --upgrade langchain import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file # Note: LLM's do not always produce the same results. When executing the code in your notebook, you may get slightly different answers that those in the video.# account for deprecation of LLM model import datetime # Get the current date current_date = datetime.datetime.now().date() # Define the date after which the model should be set to "gpt-3.5-turbo" target_date = datetime.date(2024, 6, 12) # Set the model variable based on the current date if current_date > target_date: llm_model = "gpt-3.5-turbo" else: llm_model = "gpt-3.5-turbo-0301" from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.document_loaders import CSVLoader from langchain.vectorstores import DocArrayInMemorySearch from IPython.display import display, Markdown file = 'OutdoorClothingCatalog_1000.csv' loader = CSVLoader(file_path=file) from langchain.indexes import VectorstoreIndexCreator #pip install docarray index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader]) query ="Please list all your shirts with sun protection \ in a table in markdown and summarize each one." response = index.query(query) display(Markdown(response)) # ## Step By Stepfrom langchain.document_loaders import CSVLoader loader = CSVLoader(file_path=file) docs = loader.load() docs[0] from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings() embed = embeddings.embed_query("Hi my name is Harrison") print(len(embed)) print(embed[:5]) db = DocArrayInMemorySearch.from_documents( docs, embeddings ) query = "Please suggest a shirt with sunblocking" docs = db.similarity_search(query) len(docs) docs[0] retriever = db.as_retriever() llm = ChatOpenAI(temperature = 0.0, model=llm_model) qdocs = "".join([docs[i].page_content for i in range(len(docs))]) response = llm.call_as_llm(f"{qdocs} Question: Please list all your \ shirts with sun protection in a table in markdown and summarize each one.") display(Markdown(response)) qa_stuff = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, verbose=True ) query = "Please list all your shirts with sun protection in a table \ in markdown and summarize each one." response = qa_stuff.run(query) display(Markdown(response)) response = index.query(query, llm=llm) index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch, embedding=embeddings, ).from_loaders([loader]) # Reminder: Download your notebook to you local computer to save your work.
This is to upload documents and answer questions on top of those.
- LLMs can only inspect a few thousand words at a time.
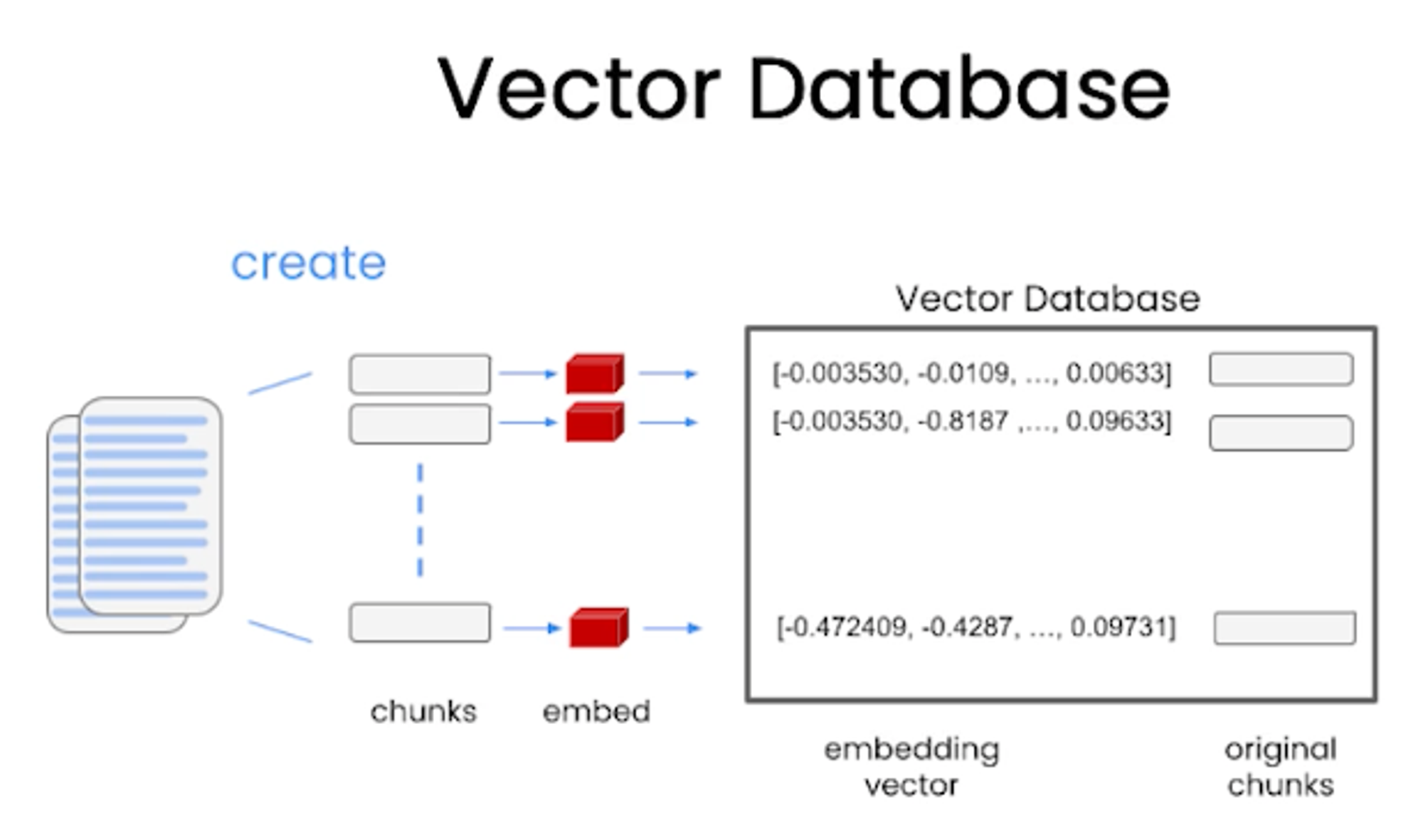
- Embedding vector captures content/meaning; Text with similar content will have similar vectors.
- Vector stores these embeddings in chunks.
- When a query comes, the vector database finds the most relevant chunks and passes those to the LLM.

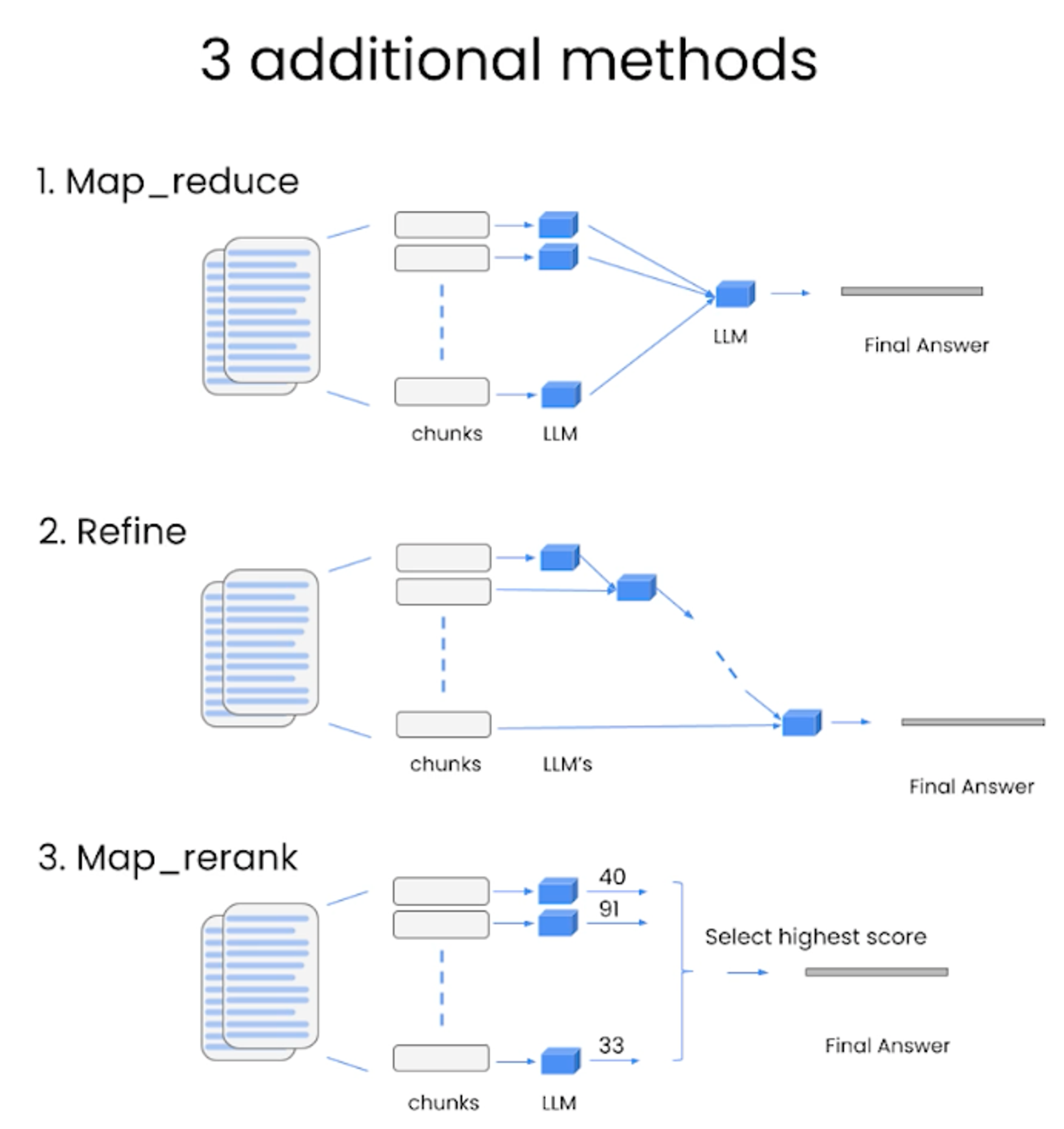
- Stuff method is the simplest method to do document Q&A.
- The other three methods are:
- Map_reduce → Chunks are passed on to LLMs in parallel → Another LLM combines the response from all the LLMs and prepares a final response. → Used in SUmmarization
- Refine → On every chunk, the LLM refines the response. It is series and time-consuming.
- Map_rerank → LLM assigns a score, and the highest-scored response is selected.



Evaluation
Notebook Code
#!/usr/bin/env python # coding: utf-8 # # LangChain: Evaluation # # ## Outline: # # * Example generation # * Manual evaluation (and debuging) # * LLM-assisted evaluation # * LangChain evaluation platform import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file# Note: LLM's do not always produce the same results. When executing the code in your notebook, you may get slightly different answers that those in the video. # account for deprecation of LLM model import datetime # Get the current date current_date = datetime.datetime.now().date() # Define the date after which the model should be set to "gpt-3.5-turbo" target_date = datetime.date(2024, 6, 12) # Set the model variable based on the current date if current_date > target_date: llm_model = "gpt-3.5-turbo" else: llm_model = "gpt-3.5-turbo-0301"# ## Create our QandA application from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.document_loaders import CSVLoader from langchain.indexes import VectorstoreIndexCreator from langchain.vectorstores import DocArrayInMemorySearch file = 'OutdoorClothingCatalog_1000.csv' loader = CSVLoader(file_path=file) data = loader.load() index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader]) llm = ChatOpenAI(temperature = 0.0, model=llm_model) qa = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=index.vectorstore.as_retriever(), verbose=True, chain_type_kwargs = { "document_separator": "<<<<>>>>>" } )# ### Coming up with test datapoints data[10] data[11]# ### Hard-coded examples examples = [ { "query": "Do the Cozy Comfort Pullover Set\ have side pockets?", "answer": "Yes" }, { "query": "What collection is the Ultra-Lofty \ 850 Stretch Down Hooded Jacket from?", "answer": "The DownTek collection" } ]# ### LLM-Generated examples from langchain.evaluation.qa import QAGenerateChain example_gen_chain = QAGenerateChain.from_llm(ChatOpenAI(model=llm_model)) # the warning below can be safely ignored new_examples = example_gen_chain.apply_and_parse( [{"doc": t} for t in data[:5]] ) new_examples[0] data[0]# ### Combine examples examples += new_examples qa.run(examples[0]["query"])# ## Manual Evaluation import langchain langchain.debug = True qa.run(examples[0]["query"]) # Turn off the debug mode langchain.debug = False# ## LLM assisted evaluation predictions = qa.apply(examples) from langchain.evaluation.qa import QAEvalChain llm = ChatOpenAI(temperature=0, model=llm_model) eval_chain = QAEvalChain.from_llm(llm) graded_outputs = eval_chain.evaluate(examples, predictions) for i, eg in enumerate(examples): print(f"Example {i}:") print("Question: " + predictions[i]['query']) print("Real Answer: " + predictions[i]['answer']) print("Predicted Answer: " + predictions[i]['result']) print("Predicted Grade: " + graded_outputs[i]['text']) print() graded_outputs[0]# ## LangChain evaluation platform # The LangChain evaluation platform, LangChain Plus, can be accessed here https://www.langchain.plus/. # Use the invite code `lang_learners_2023` # Reminder: Download your notebook to you local computer to save your work.
Agents
Notebook Code
import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file import warnings warnings.filterwarnings("ignore") # account for deprecation of LLM model import datetime # Get the current date current_date = datetime.datetime.now().date() # Define the date after which the model should be set to "gpt-3.5-turbo" target_date = datetime.date(2024, 6, 12) # Set the model variable based on the current date if current_date > target_date: llm_model = "gpt-3.5-turbo" else: llm_model = "gpt-3.5-turbo-0301" # Built-in LangChain tools #!pip install -U wikipedia from langchain.agents.agent_toolkits import create_python_agent from langchain.agents import load_tools, initialize_agent from langchain.agents import AgentType from langchain.tools.python.tool import PythonREPLTool from langchain.python import PythonREPL from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model=llm_model) tools = load_tools(["llm-math","wikipedia"], llm=llm) agent= initialize_agent( tools, llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True, verbose = True) agent("What is the 25% of 300?") question = "Tom M. Mitchell is an American computer scientist \ and the Founders University Professor at Carnegie Mellon University (CMU)\ what book did he write?" result = agent(question) agent = create_python_agent( llm, tool=PythonREPLTool(), verbose=True ) customer_list = [["Harrison", "Chase"], ["Lang", "Chain"], ["Dolly", "Too"], ["Elle", "Elem"], ["Geoff","Fusion"], ["Trance","Former"], ["Jen","Ayai"] ] agent.run(f"""Sort these customers by \ last name and then first name \ and print the output: {customer_list}""") import langchain langchain.debug=True agent.run(f"""Sort these customers by \ last name and then first name \ and print the output: {customer_list}""") langchain.debug=False # Define your own tool #!pip install DateTime from langchain.agents import tool from datetime import date @tool def time(text: str) -> str: """Returns todays date, use this for any \ questions related to knowing todays date. \ The input should always be an empty string, \ and this function will always return todays \ date - any date mathmatics should occur \ outside this function.""" return str(date.today()) agent= initialize_agent( tools + [time], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True, verbose = True) """ Note: The agent will sometimes come to the wrong conclusion (agents are a work in progress!). If it does, please try running it again. """ try: result = agent("whats the date today?") except: print("exception on external access")
⚠️Disclaimer: All the screenshots, materials, and other media documents used in this article are copyrighted to the original platform or authors.