

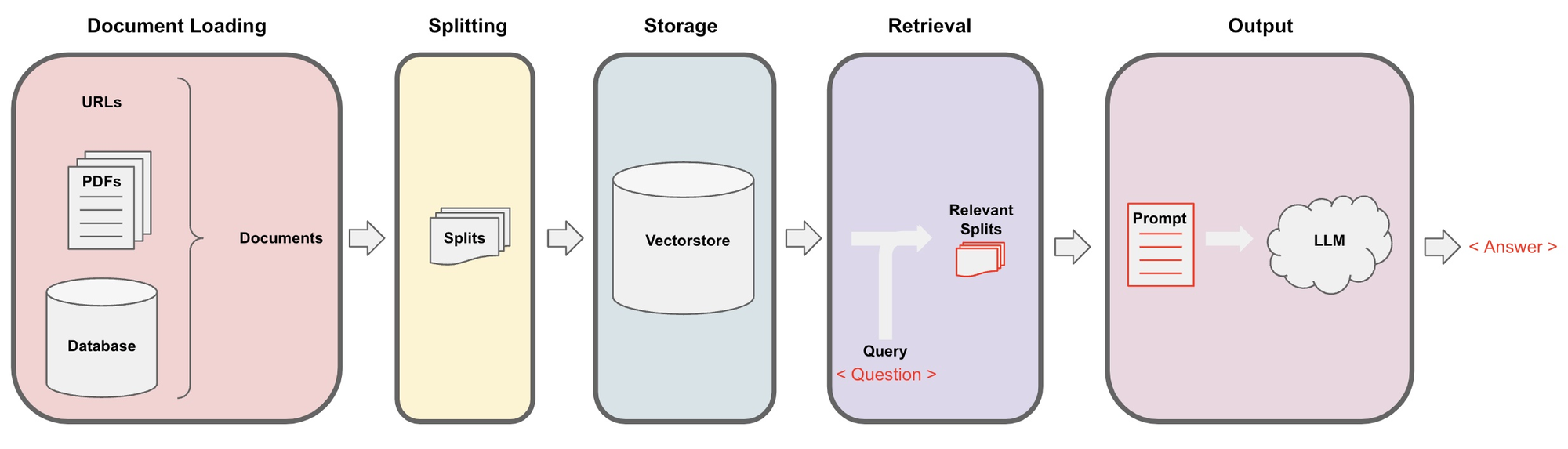
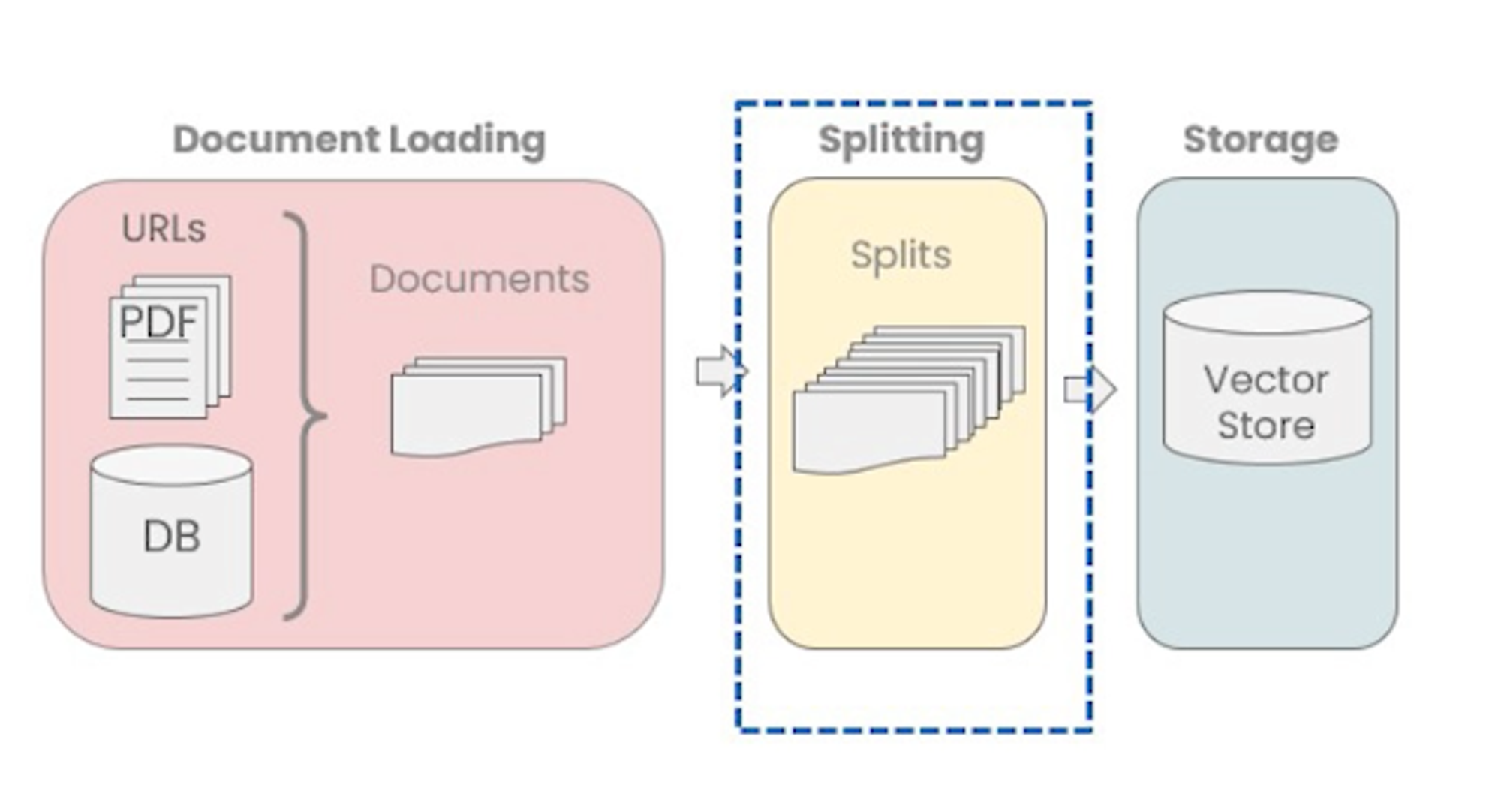
Document Loading
Notebook Code
#!/usr/bin/env python # coding: utf-8 # # Document Loading # ## Note to students. # During periods of high load you may find the notebook unresponsive. It may appear to execute a cell, update the completion number in brackets [#] at the left of the cell but you may find the cell has not executed. This is particularly obvious on print statements when there is no output. If this happens, restart the kernel using the command under the Kernel tab. # ## Retrieval augmented generation # # In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution. # # This is useful if we want to ask question about specific documents (e.g., our PDFs, a set of videos, etc). #  #! pip install langchain import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY']# ## PDFs # # Let's load a PDF [transcript](https://see.stanford.edu/materials/aimlcs229/transcripts/MachineLearning-Lecture01.pdf) from Andrew Ng's famous CS229 course! These documents are the result of automated transcription so words and sentences are sometimes split unexpectedly. # The course will show the pip installs you would need to install packages on your own machine. # These packages are already installed on this platform and should not be run again. #! pip install pypdf from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf") pages = loader.load()# Each page is a `Document`. # # A `Document` contains text (`page_content`) and `metadata`. len(pages) page = pages[0] print(page.page_content[0:500]) page.metadata# ## YouTube from langchain.document_loaders.generic import GenericLoader from langchain.document_loaders.parsers import OpenAIWhisperParser from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader # ! pip install yt_dlp # ! pip install pydub# **Note**: This can take several minutes to complete. url="https://www.youtube.com/watch?v=jGwO_UgTS7I" save_dir="docs/youtube/" loader = GenericLoader( YoutubeAudioLoader([url],save_dir), OpenAIWhisperParser() ) docs = loader.load() docs[0].page_content[0:500]# ## URLs from langchain.document_loaders import WebBaseLoader loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/37signals-is-you.md") docs = loader.load() print(docs[0].page_content[:500])# ## Notion # Follow steps [here](https://python.langchain.com/docs/modules/data_connection/document_loaders/integrations/notion) for an example Notion site such as [this one](https://yolospace.notion.site/Blendle-s-Employee-Handbook-e31bff7da17346ee99f531087d8b133f): # # * Duplicate the page into your own Notion space and export as `Markdown / CSV`. # * Unzip it and save it as a folder that contains the markdown file for the Notion page. # #  from langchain.document_loaders import NotionDirectoryLoader loader = NotionDirectoryLoader("docs/Notion_DB") docs = loader.load() print(docs[0].page_content[0:200]) docs[0].metadata


Notebook Code
#!/usr/bin/env python # coding: utf-8 # # Document Loading # ## Note to students. # During periods of high load you may find the notebook unresponsive. It may appear to execute a cell, update the completion number in brackets [#] at the left of the cell but you may find the cell has not executed. This is particularly obvious on print statements when there is no output. If this happens, restart the kernel using the command under the Kernel tab. # ## Retrieval augmented generation # # In retrieval augmented generation (RAG), an LLM retrieves contextual documents from an external dataset as part of its execution. # # This is useful if we want to ask question about specific documents (e.g., our PDFs, a set of videos, etc). #  #! pip install langchain import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY']# ## PDFs # # Let's load a PDF [transcript](https://see.stanford.edu/materials/aimlcs229/transcripts/MachineLearning-Lecture01.pdf) from Andrew Ng's famous CS229 course! These documents are the result of automated transcription so words and sentences are sometimes split unexpectedly. # The course will show the pip installs you would need to install packages on your own machine. # These packages are already installed on this platform and should not be run again. #! pip install pypdf from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf") pages = loader.load()# Each page is a `Document`. # # A `Document` contains text (`page_content`) and `metadata`. len(pages) page = pages[0] print(page.page_content[0:500]) page.metadata# ## YouTube from langchain.document_loaders.generic import GenericLoader from langchain.document_loaders.parsers import OpenAIWhisperParser from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader # ! pip install yt_dlp # ! pip install pydub# **Note**: This can take several minutes to complete. url="https://www.youtube.com/watch?v=jGwO_UgTS7I" save_dir="docs/youtube/" loader = GenericLoader( YoutubeAudioLoader([url],save_dir), OpenAIWhisperParser() ) docs = loader.load() docs[0].page_content[0:500]# ## URLs from langchain.document_loaders import WebBaseLoader loader = WebBaseLoader("https://github.com/basecamp/handbook/blob/master/37signals-is-you.md") docs = loader.load() print(docs[0].page_content[:500])# ## Notion # Follow steps [here](https://python.langchain.com/docs/modules/data_connection/document_loaders/integrations/notion) for an example Notion site such as [this one](https://yolospace.notion.site/Blendle-s-Employee-Handbook-e31bff7da17346ee99f531087d8b133f): # # * Duplicate the page into your own Notion space and export as `Markdown / CSV`. # * Unzip it and save it as a folder that contains the markdown file for the Notion page. # #  from langchain.document_loaders import NotionDirectoryLoader loader = NotionDirectoryLoader("docs/Notion_DB") docs = loader.load() print(docs[0].page_content[0:200]) docs[0].metadata
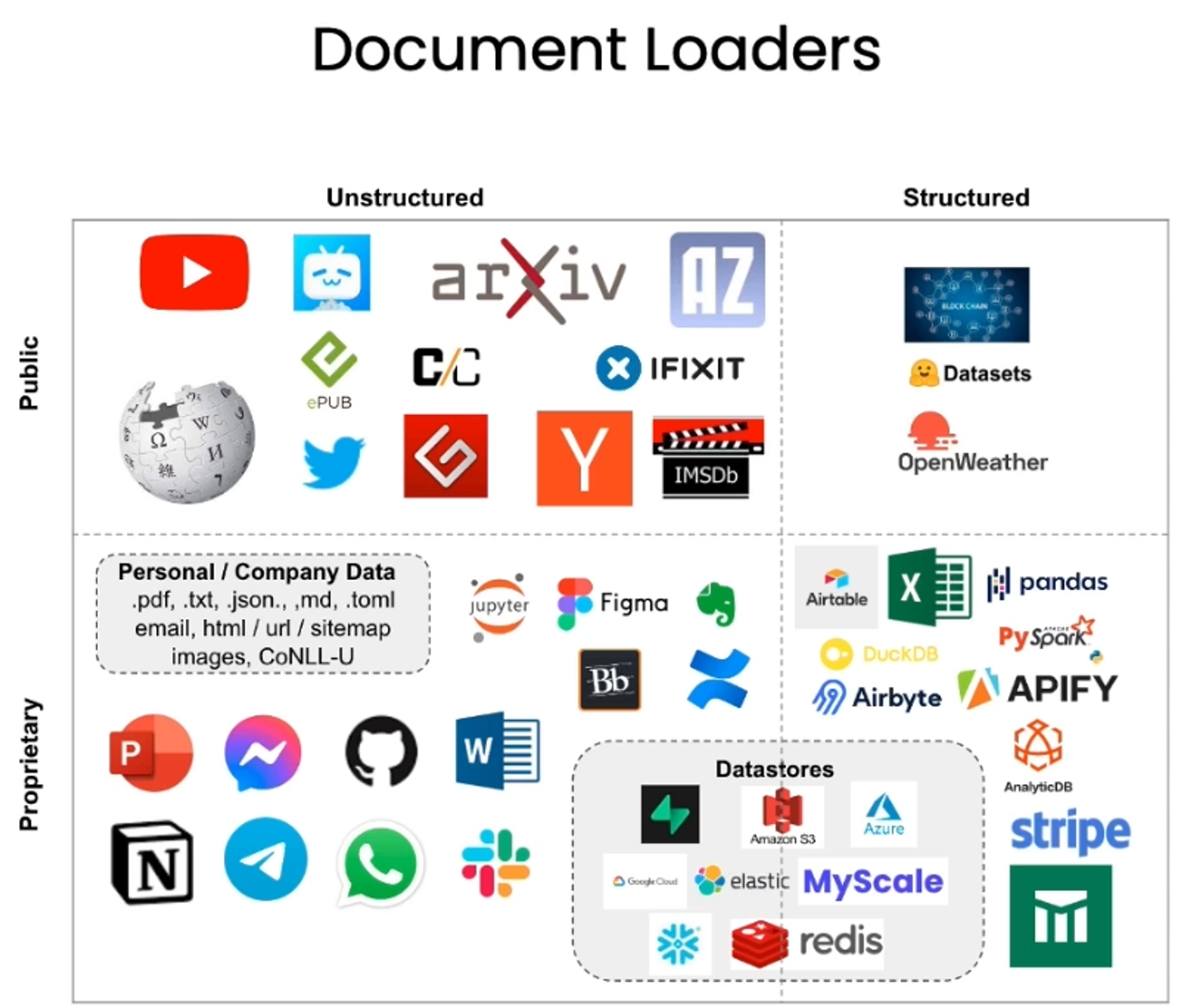
- There are various kinds of document fetchers in Langchain:
- PDF, Youtube, Webpage, Notion
Document Splitting
Notebook Code
#!/usr/bin/env python # coding: utf-8 # # Document Splitting import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] from langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter chunk_size =26 chunk_overlap = 4 r_splitter = RecursiveCharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap ) c_splitter = CharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap )# Why doesn't this split the string below? text1 = 'abcdefghijklmnopqrstuvwxyz' r_splitter.split_text(text1) text2 = 'abcdefghijklmnopqrstuvwxyzabcdefg' r_splitter.split_text(text2)# Ok, this splits the string but we have an overlap specified as 5, but it looks like 3? (try an even number) text3 = "a b c d e f g h i j k l m n o p q r s t u v w x y z" r_splitter.split_text(text3) # ['a b c d e f g h i j k l m', 'l m n o p q r s t u v w x', 'w x y z'] c_splitter.split_text(text3) # ['a b c d e f g h i j k l m n o p q r s t u v w x y z'] c_splitter = CharacterTextSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator = ' ' ) c_splitter.split_text(text3)# Try your own examples! # ## Recursive splitting details # # `RecursiveCharacterTextSplitter` is recommended for generic text. some_text = """When writing documents, writers will use document structure to group content. \ This can convey to the reader, which idea's are related. For example, closely related ideas \ are in sentances. Similar ideas are in paragraphs. Paragraphs form a document. \n\n \ Paragraphs are often delimited with a carriage return or two carriage returns. \ Carriage returns are the "backslash n" you see embedded in this string. \ Sentences have a period at the end, but also, have a space.\ and words are separated by space.""" len(some_text) c_splitter = CharacterTextSplitter( chunk_size=450, chunk_overlap=0, separator = ' ' ) r_splitter = RecursiveCharacterTextSplitter( chunk_size=450, chunk_overlap=0, separators=["\n\n", "\n", " ", ""] ) c_splitter.split_text(some_text) r_splitter.split_text(some_text)# Let's reduce the chunk size a bit and add a period to our separators: r_splitter = RecursiveCharacterTextSplitter( chunk_size=150, chunk_overlap=0, separators=["\n\n", "\n", "\. ", " ", ""] ) r_splitter.split_text(some_text) r_splitter = RecursiveCharacterTextSplitter( chunk_size=150, chunk_overlap=0, separators=["\n\n", "\n", "(?<=\. )", " ", ""] ) r_splitter.split_text(some_text) from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf") pages = loader.load() from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="\n", chunk_size=1000, chunk_overlap=150, length_function=len ) docs = text_splitter.split_documents(pages) len(docs) len(pages) from langchain.document_loaders import NotionDirectoryLoader loader = NotionDirectoryLoader("docs/Notion_DB") notion_db = loader.load() docs = text_splitter.split_documents(notion_db) len(notion_db) len(docs)# ## Token splitting # # We can also split on token count explicity, if we want. # # This can be useful because LLMs often have context windows designated in tokens. # # Tokens are often ~4 characters. from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=1, chunk_overlap=0) text1 = "foo bar bazzyfoo" text_splitter.split_text(text1) text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0) docs = text_splitter.split_documents(pages) docs[0] pages[0].metadata# ## Context aware splitting # # Chunking aims to keep text with common context together. # # A text splitting often uses sentences or other delimiters to keep related text together but many documents (such as Markdown) have structure (headers) that can be explicitly used in splitting. # # We can use `MarkdownHeaderTextSplitter` to preserve header metadata in our chunks, as show below. from langchain.document_loaders import NotionDirectoryLoader from langchain.text_splitter import MarkdownHeaderTextSplitter markdown_document = """# Title\n\n \ ## Chapter 1\n\n \ Hi this is Jim\n\n Hi this is Joe\n\n \ ### Section \n\n \ Hi this is Lance \n\n ## Chapter 2\n\n \ Hi this is Molly""" headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3"), ] markdown_splitter = MarkdownHeaderTextSplitter( headers_to_split_on=headers_to_split_on ) md_header_splits = markdown_splitter.split_text(markdown_document) md_header_splits[0] md_header_splits[1]# Try on a real Markdown file, like a Notion database. loader = NotionDirectoryLoader("docs/Notion_DB") docs = loader.load() txt = ' '.join([d.page_content for d in docs]) headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ] markdown_splitter = MarkdownHeaderTextSplitter( headers_to_split_on=headers_to_split_on ) md_header_splits = markdown_splitter.split_text(txt) md_header_splits[0]





Vector Store and Embeddings
Notebook code
#!/usr/bin/env python # coding: utf-8 # # Vectorstores and Embeddings # # Recall the overall workflow for retrieval augmented generation (RAG): #  import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY']# We just discussed `Document Loading` and `Splitting`. from langchain.document_loaders import PyPDFLoader # Load PDF loaders = [ # Duplicate documents on purpose - messy data PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"), PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf"), PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture02.pdf"), PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture03.pdf") ] docs = [] for loader in loaders: docs.extend(loader.load()) # Split from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size = 1500, chunk_overlap = 150 ) splits = text_splitter.split_documents(docs) len(splits)# ## Embeddings # # Let's take our splits and embed them. from langchain.embeddings.openai import OpenAIEmbeddings embedding = OpenAIEmbeddings() sentence1 = "i like dogs" sentence2 = "i like canines" sentence3 = "the weather is ugly outside" embedding1 = embedding.embed_query(sentence1) embedding2 = embedding.embed_query(sentence2) embedding3 = embedding.embed_query(sentence3) import numpy as np np.dot(embedding1, embedding2) np.dot(embedding1, embedding3) np.dot(embedding2, embedding3)# ## Vectorstores # ! pip install chromadb from langchain.vectorstores import Chroma persist_directory = 'docs/chroma/' get_ipython().system('rm -rf ./docs/chroma # remove old database files if any') vectordb = Chroma.from_documents( documents=splits, embedding=embedding, persist_directory=persist_directory ) print(vectordb._collection.count())# ### Similarity Search question = "is there an email i can ask for help" docs = vectordb.similarity_search(question,k=3) len(docs) docs[0].page_content# Let's save this so we can use it later! vectordb.persist()# ## Failure modes # # This seems great, and basic similarity search will get you 80% of the way there very easily. # # But there are some failure modes that can creep up. # # Here are some edge cases that can arise - we'll fix them in the next class. question = "what did they say about matlab?" docs = vectordb.similarity_search(question,k=5)# Notice that we're getting duplicate chunks (because of the duplicate `MachineLearning-Lecture01.pdf` in the index). # # Semantic search fetches all similar documents, but does not enforce diversity. # # `docs[0]` and `docs[1]` are indentical. docs[0] docs[1]# We can see a new failure mode. # # The question below asks a question about the third lecture, but includes results from other lectures as well. question = "what did they say about regression in the third lecture?" docs = vectordb.similarity_search(question,k=5) for doc in docs: print(doc.metadata) print(docs[4].page_content)# Approaches discussed in the next lecture can be used to address both!
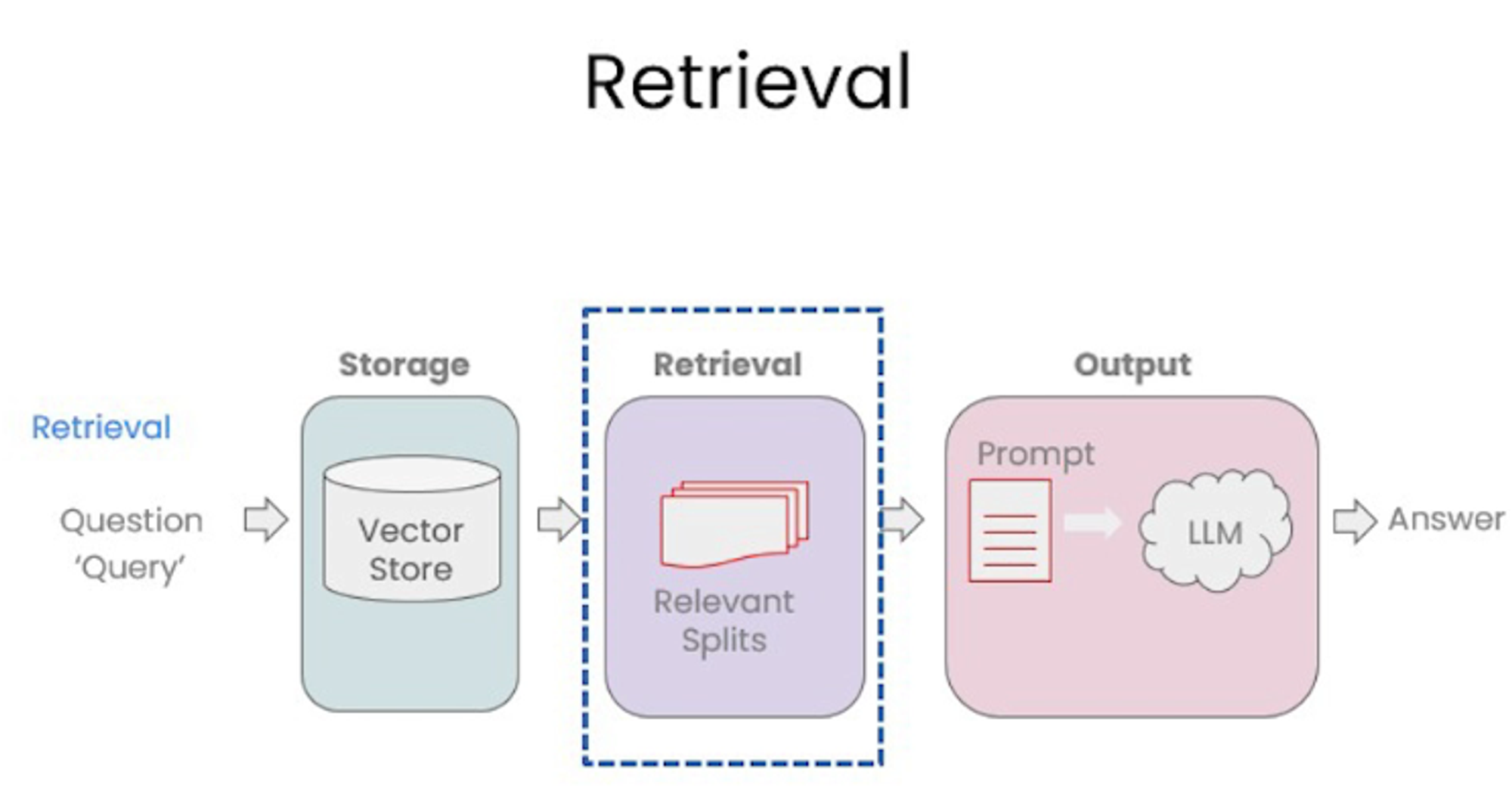
Retrieval
Notebook Code
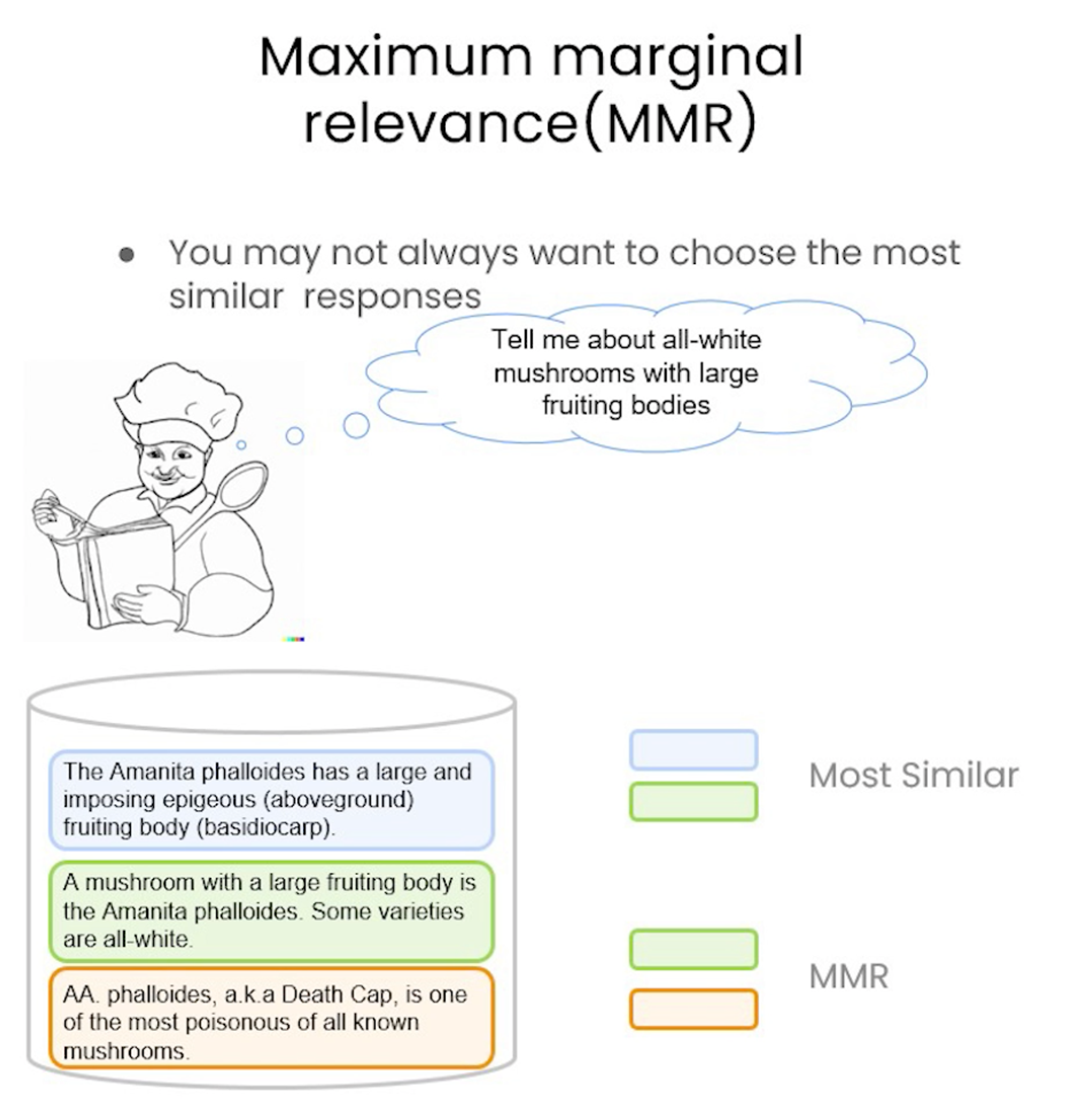
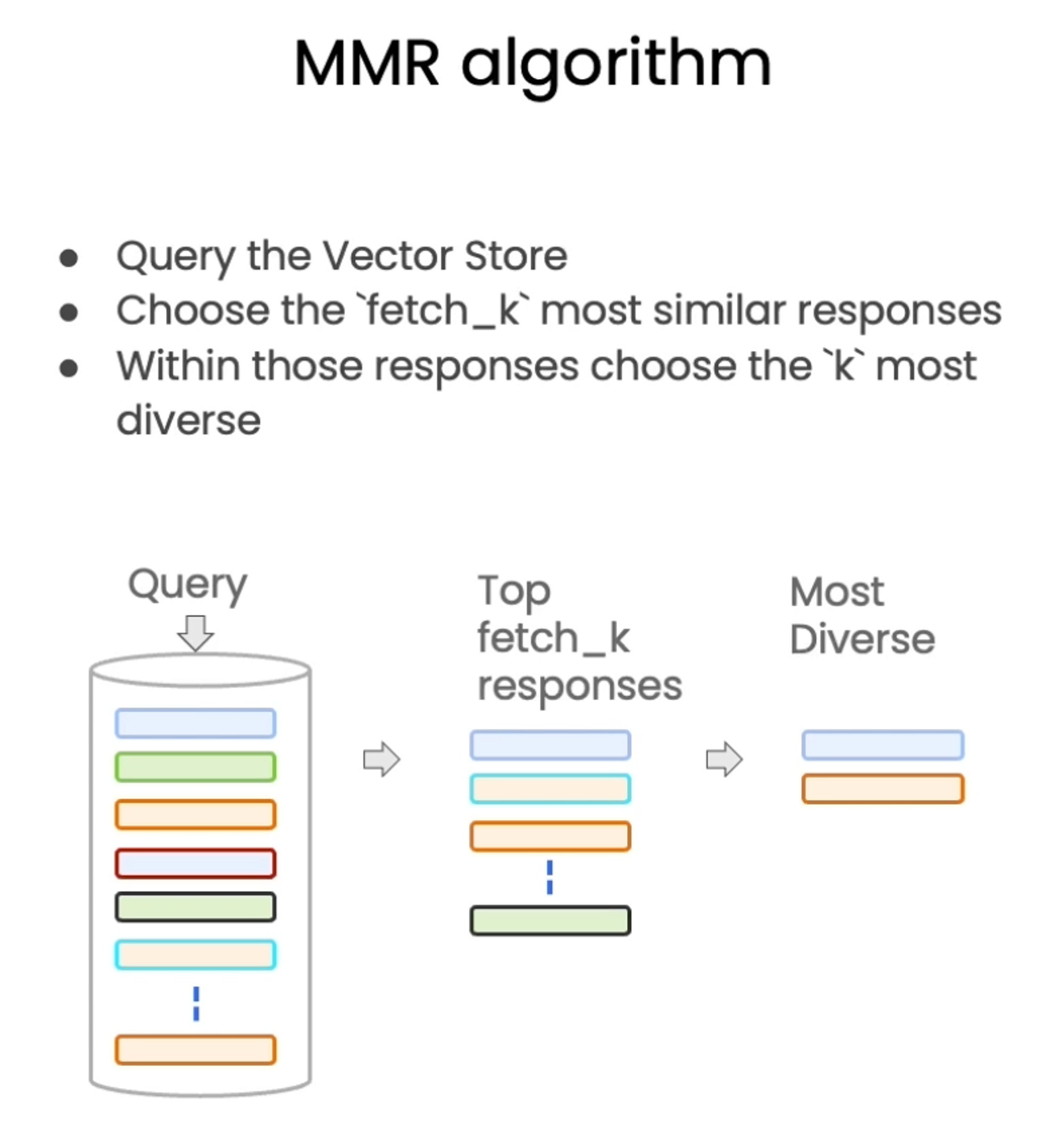
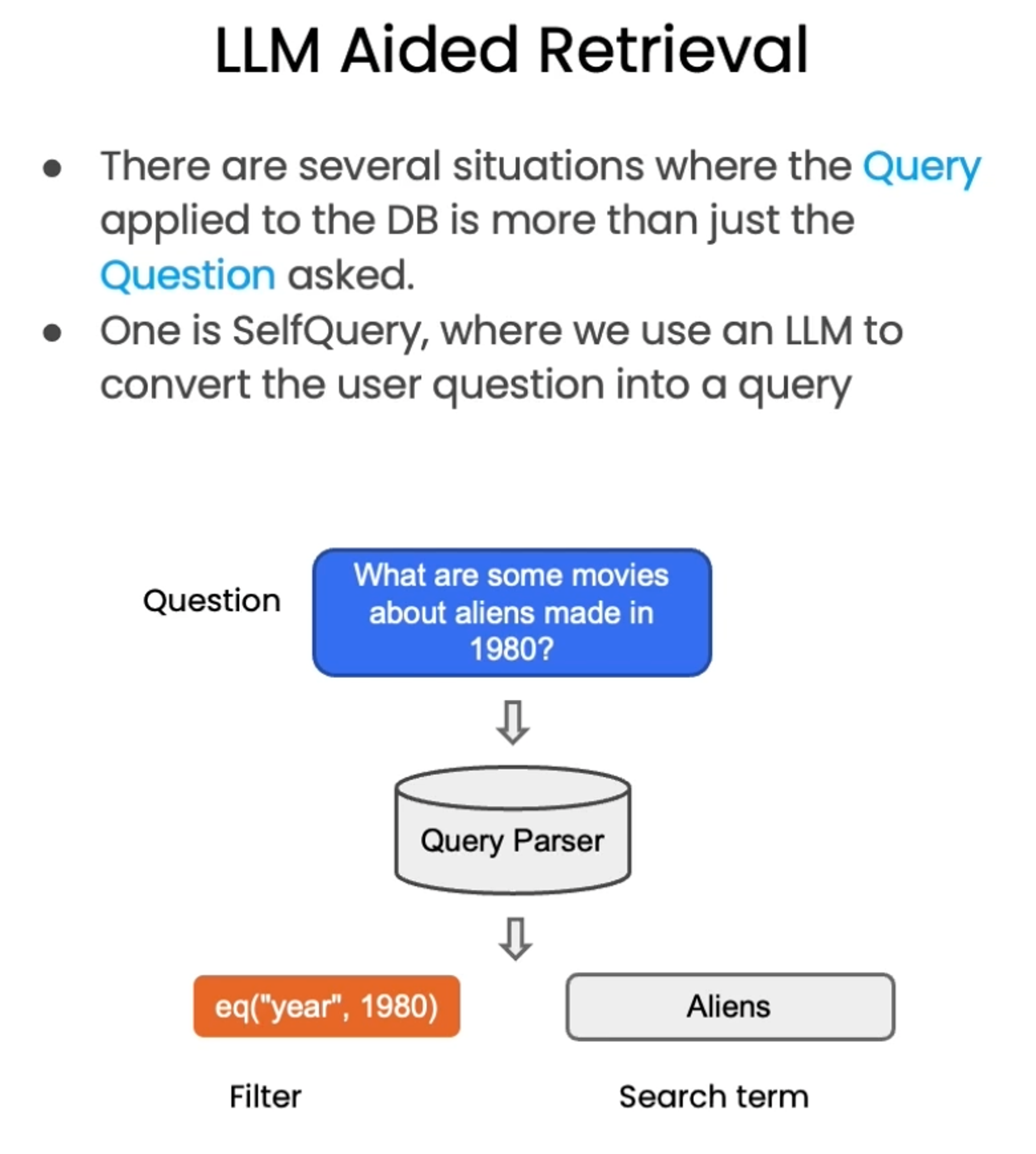
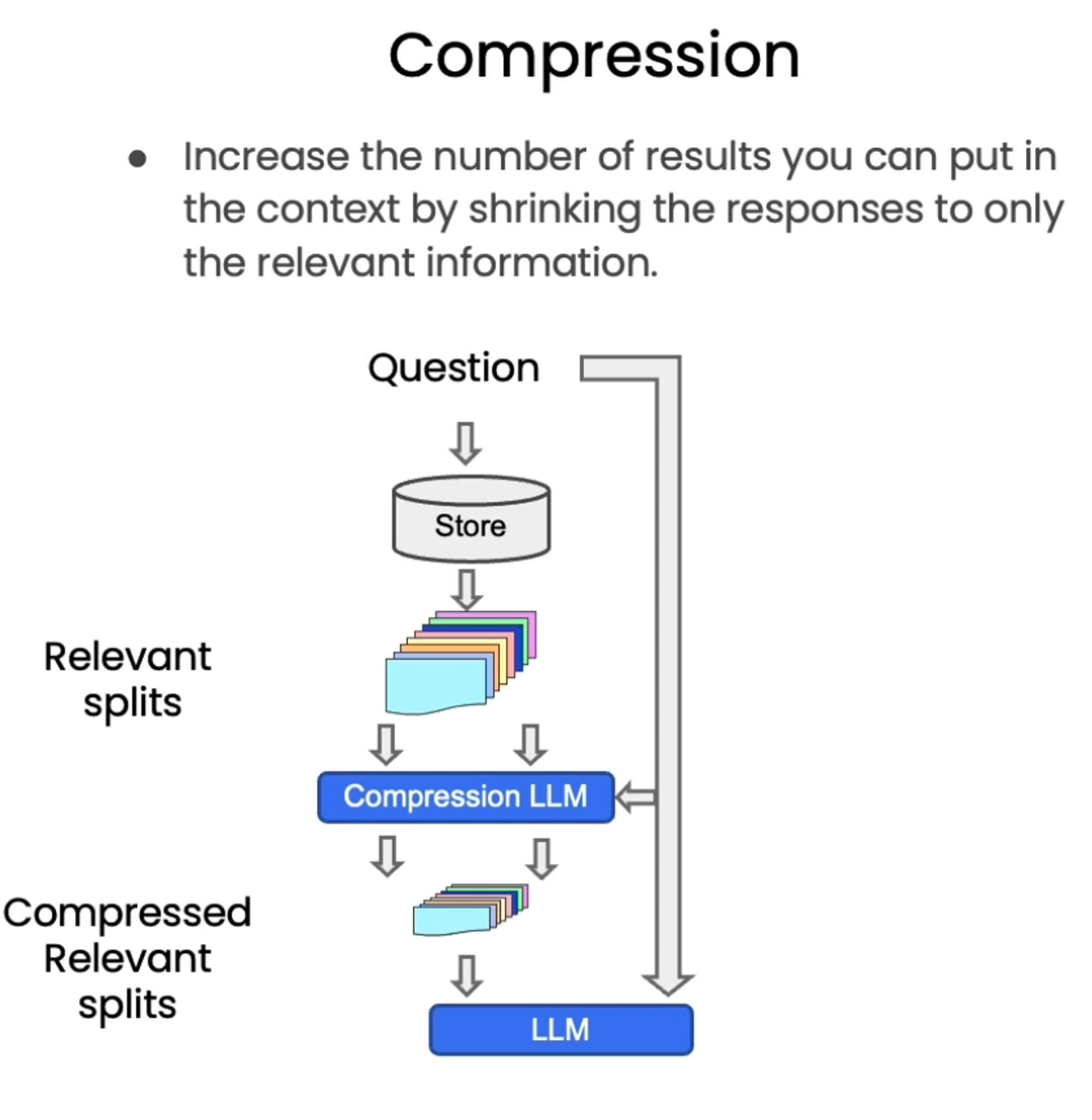
#!/usr/bin/env python # coding: utf-8 # # Retrieval # # Retrieval is the centerpiece of our retrieval augmented generation (RAG) flow. # # Let's get our vectorDB from before. # ## Vectorstore retrieval # import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] #!pip install lark# ### Similarity Search from langchain.vectorstores import Chroma from langchain.embeddings.openai import OpenAIEmbeddings persist_directory = 'docs/chroma/' embedding = OpenAIEmbeddings() vectordb = Chroma( persist_directory=persist_directory, embedding_function=embedding ) print(vectordb._collection.count()) texts = [ """The Amanita phalloides has a large and imposing epigeous (aboveground) fruiting body (basidiocarp).""", """A mushroom with a large fruiting body is the Amanita phalloides. Some varieties are all-white.""", """A. phalloides, a.k.a Death Cap, is one of the most poisonous of all known mushrooms.""", ] smalldb = Chroma.from_texts(texts, embedding=embedding) question = "Tell me about all-white mushrooms with large fruiting bodies" smalldb.similarity_search(question, k=2) smalldb.max_marginal_relevance_search(question,k=2, fetch_k=3)# ### Addressing Diversity: Maximum marginal relevance # # Last class we introduced one problem: how to enforce diversity in the search results. # # `Maximum marginal relevance` strives to achieve both relevance to the query *and diversity* among the results. question = "what did they say about matlab?" docs_ss = vectordb.similarity_search(question,k=3) docs_ss[0].page_content[:100] docs_ss[1].page_content[:100]# Note the difference in results with `MMR`. docs_mmr = vectordb.max_marginal_relevance_search(question,k=3) docs_mmr[0].page_content[:100] docs_mmr[1].page_content[:100]# ### Addressing Specificity: working with metadata # # In last lecture, we showed that a question about the third lecture can include results from other lectures as well. # # To address this, many vectorstores support operations on `metadata`. # # `metadata` provides context for each embedded chunk. question = "what did they say about regression in the third lecture?" docs = vectordb.similarity_search( question, k=3, filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"} ) for d in docs: print(d.metadata) # ### Addressing Specificity: working with metadata using self-query retriever # # But we have an interesting challenge: we often want to infer the metadata from the query itself. # # To address this, we can use `SelfQueryRetriever`, which uses an LLM to extract: # # 1. The `query` string to use for vector search # 2. A metadata filter to pass in as well # # Most vector databases support metadata filters, so this doesn't require any new databases or indexes. from langchain.llms import OpenAI from langchain.retrievers.self_query.base import SelfQueryRetriever from langchain.chains.query_constructor.base import AttributeInfo metadata_field_info = [ AttributeInfo( name="source", description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`", type="string", ), AttributeInfo( name="page", description="The page from the lecture", type="integer", ), ] document_content_description = "Lecture notes" llm = OpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm( llm, vectordb, document_content_description, metadata_field_info, verbose=True ) question = "what did they say about regression in the third lecture?"# **You will receive a warning** about predict_and_parse being deprecated the first time you executing the next line. This can be safely ignored. docs = retriever.get_relevant_documents(question) for d in docs: print(d.metadata)# ### Additional tricks: compression # # Another approach for improving the quality of retrieved docs is compression. # # Information most relevant to a query may be buried in a document with a lot of irrelevant text. # # Passing that full document through your application can lead to more expensive LLM calls and poorer responses. # # Contextual compression is meant to fix this. from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import LLMChainExtractor def pretty_print_docs(docs): print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)])) # Wrap our vectorstore llm = OpenAI(temperature=0) compressor = LLMChainExtractor.from_llm(llm) compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=vectordb.as_retriever() ) question = "what did they say about matlab?" compressed_docs = compression_retriever.get_relevant_documents(question) pretty_print_docs(compressed_docs)# ## Combining various techniques compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=vectordb.as_retriever(search_type = "mmr") ) question = "what did they say about matlab?" compressed_docs = compression_retriever.get_relevant_documents(question) pretty_print_docs(compressed_docs)# ## Other types of retrieval # # It's worth noting that vectordb as not the only kind of tool to retrieve documents. # # The `LangChain` retriever abstraction includes other ways to retrieve documents, such as TF-IDF or SVM. from langchain.retrievers import SVMRetriever from langchain.retrievers import TFIDFRetriever from langchain.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter # Load PDF loader = PyPDFLoader("docs/cs229_lectures/MachineLearning-Lecture01.pdf") pages = loader.load() all_page_text=[p.page_content for p in pages] joined_page_text=" ".join(all_page_text) # Split text_splitter = RecursiveCharacterTextSplitter(chunk_size = 1500,chunk_overlap = 150) splits = text_splitter.split_text(joined_page_text) # Retrieve svm_retriever = SVMRetriever.from_texts(splits,embedding) tfidf_retriever = TFIDFRetriever.from_texts(splits) question = "What are major topics for this class?" docs_svm=svm_retriever.get_relevant_documents(question) docs_svm[0] question = "what did they say about matlab?" docs_tfidf=tfidf_retriever.get_relevant_documents(question) docs_tfidf[0]





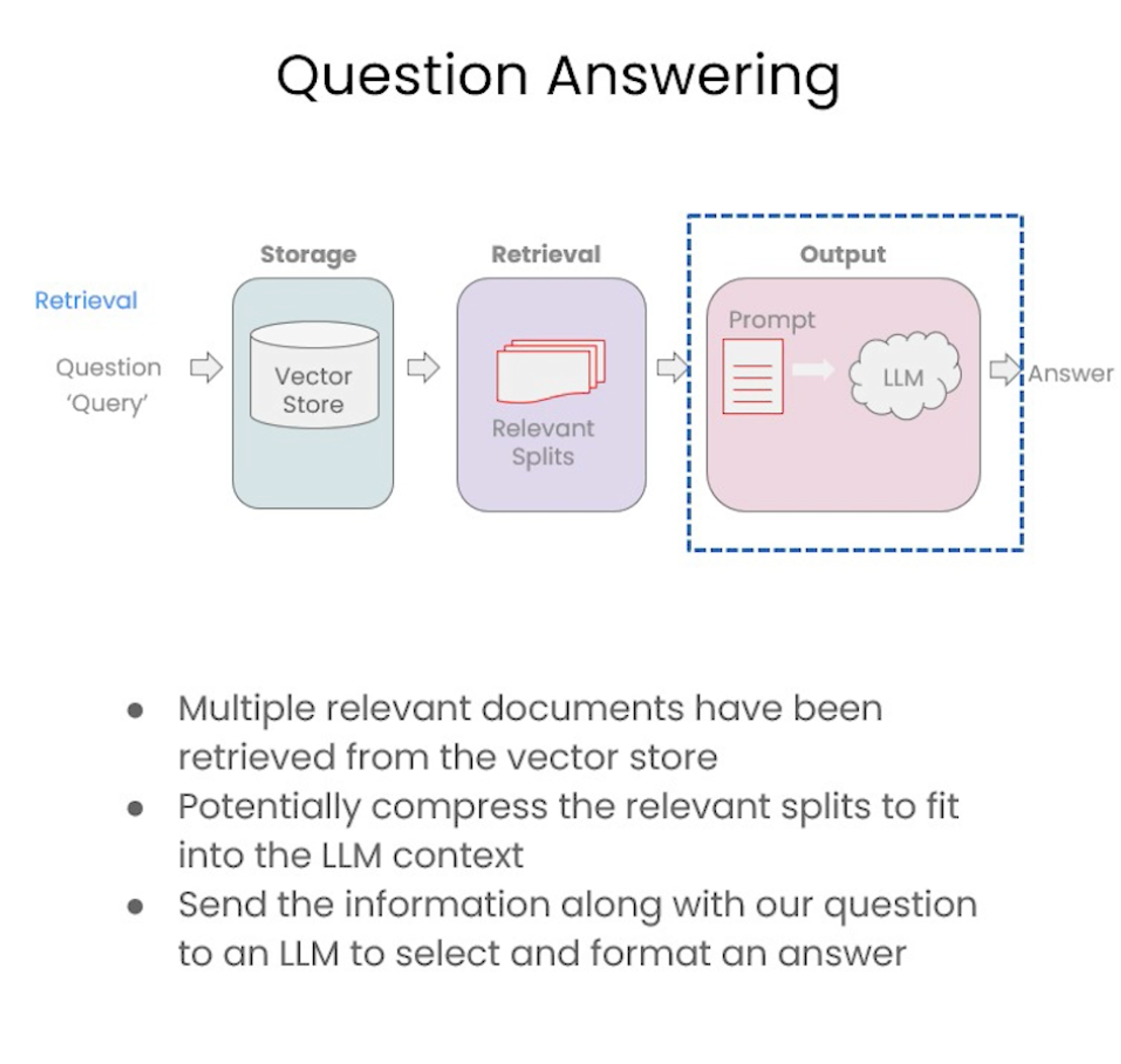
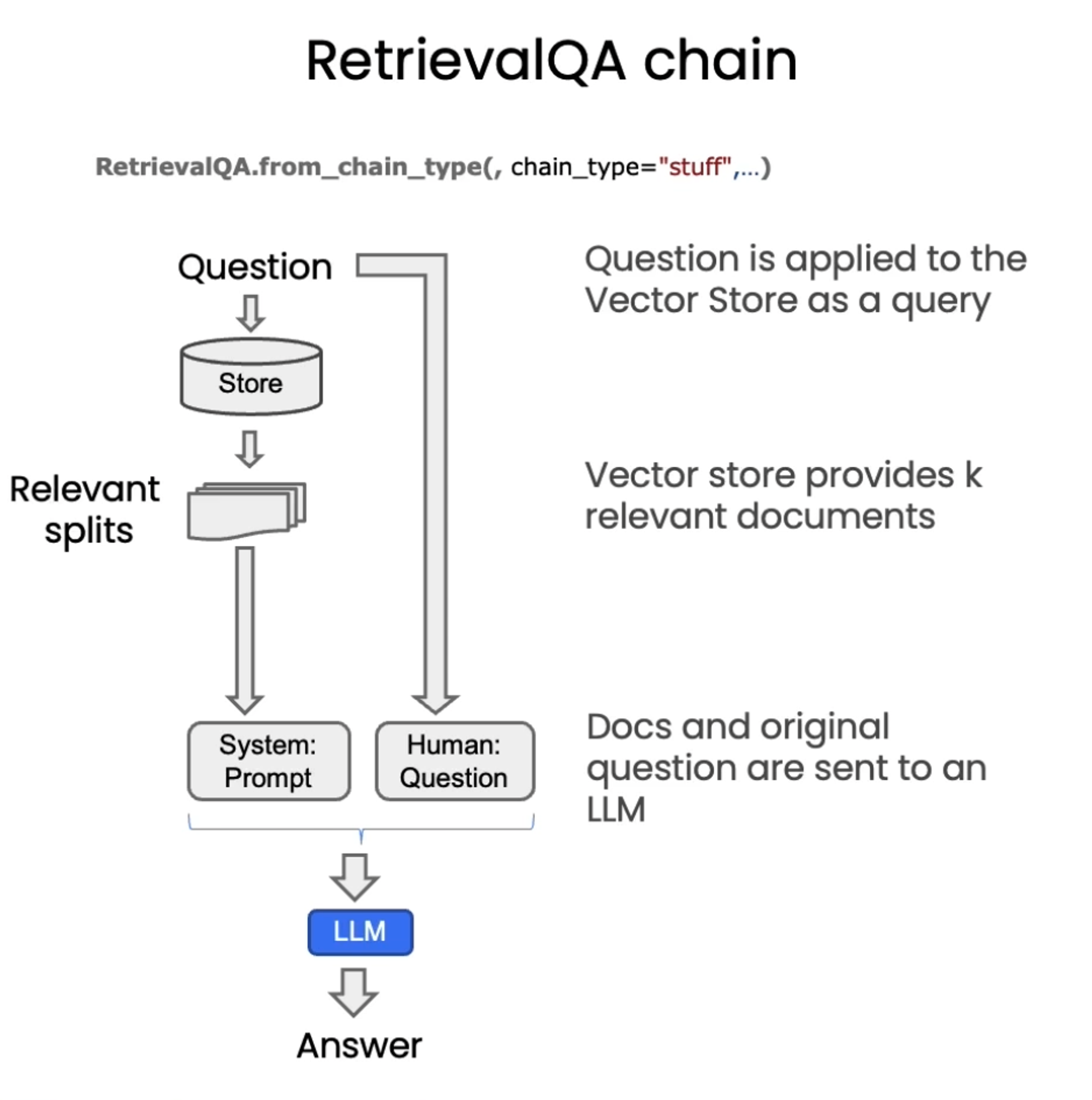
Question and Answering
Notebook Code
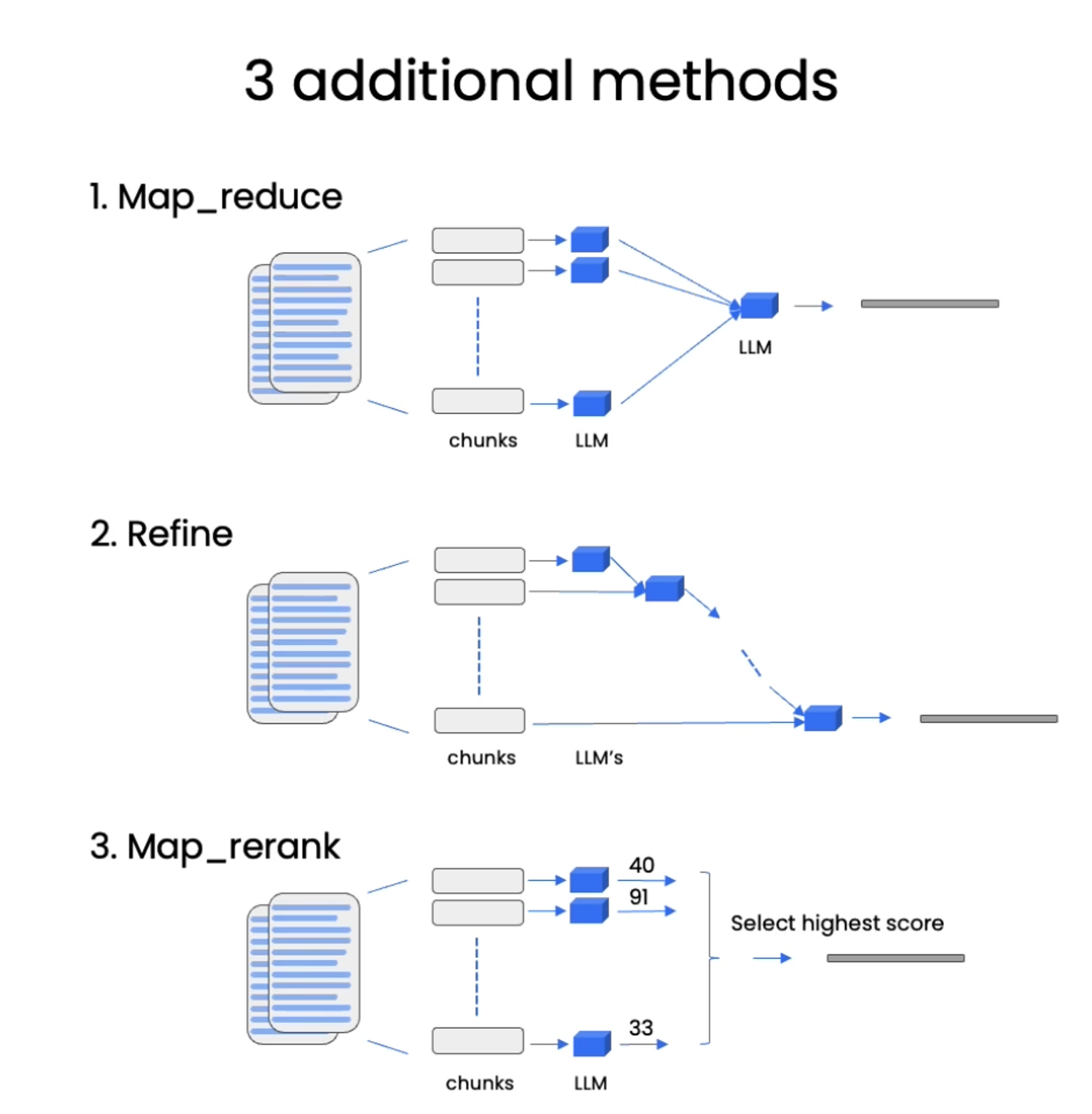
#!/usr/bin/env python # coding: utf-8 # # Question Answering # ## Overview # # Recall the overall workflow for retrieval augmented generation (RAG): #  # We discussed `Document Loading` and `Splitting` as well as `Storage` and `Retrieval`. # # Let's load our vectorDB. # In[ ]: import os import openai import sys sys.path.append('../..') from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] # The code below was added to assign the openai LLM version filmed until it is deprecated, currently in Sept 2023. # LLM responses can often vary, but the responses may be significantly different when using a different model version. # In[ ]: import datetime current_date = datetime.datetime.now().date() if current_date < datetime.date(2023, 9, 2): llm_name = "gpt-3.5-turbo-0301" else: llm_name = "gpt-3.5-turbo" print(llm_name) # In[ ]: from langchain.vectorstores import Chroma from langchain.embeddings.openai import OpenAIEmbeddings persist_directory = 'docs/chroma/' embedding = OpenAIEmbeddings() vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding) # In[ ]: print(vectordb._collection.count()) # In[ ]: question = "What are major topics for this class?" docs = vectordb.similarity_search(question,k=3) len(docs) # In[ ]: from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name=llm_name, temperature=0) # ### RetrievalQA chain # In[ ]: from langchain.chains import RetrievalQA # In[ ]: qa_chain = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever() ) # In[ ]: result = qa_chain({"query": question}) # In[ ]: result["result"] # ### Prompt # In[ ]: from langchain.prompts import PromptTemplate # Build prompt template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" QA_CHAIN_PROMPT = PromptTemplate.from_template(template) # In[ ]: # Run chain qa_chain = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever(), return_source_documents=True, chain_type_kwargs={"prompt": QA_CHAIN_PROMPT} ) # In[ ]: question = "Is probability a class topic?" # In[ ]: result = qa_chain({"query": question}) # In[ ]: result["result"] # In[ ]: result["source_documents"][0] # ### RetrievalQA chain types # In[ ]: qa_chain_mr = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever(), chain_type="map_reduce" ) # In[ ]: result = qa_chain_mr({"query": question}) # In[ ]: result["result"] # If you wish to experiment on the `LangChain plus platform`: # # * Go to [langchain plus platform](https://www.langchain.plus/) and sign up # * Create an API key from your account's settings # * Use this API key in the code below # * uncomment the code # Note, the endpoint in the video differs from the one below. Use the one below. # In[ ]: #import os #os.environ["LANGCHAIN_TRACING_V2"] = "true" #os.environ["LANGCHAIN_ENDPOINT"] = "https://api.langchain.plus" #os.environ["LANGCHAIN_API_KEY"] = "..." # replace dots with your api key # In[ ]: qa_chain_mr = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever(), chain_type="map_reduce" ) result = qa_chain_mr({"query": question}) result["result"] # In[ ]: qa_chain_mr = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever(), chain_type="refine" ) result = qa_chain_mr({"query": question}) result["result"] # ### RetrievalQA limitations # # QA fails to preserve conversational history. # In[ ]: qa_chain = RetrievalQA.from_chain_type( llm, retriever=vectordb.as_retriever() ) # In[ ]: question = "Is probability a class topic?" result = qa_chain({"query": question}) result["result"] # In[ ]: question = "why are those prerequesites needed?" result = qa_chain({"query": question}) result["result"] # Note, The LLM response varies. Some responses **do** include a reference to probability which might be gleaned from referenced documents. The point is simply that the model does not have access to past questions or answers, this will be covered in the next section. # In[ ]:



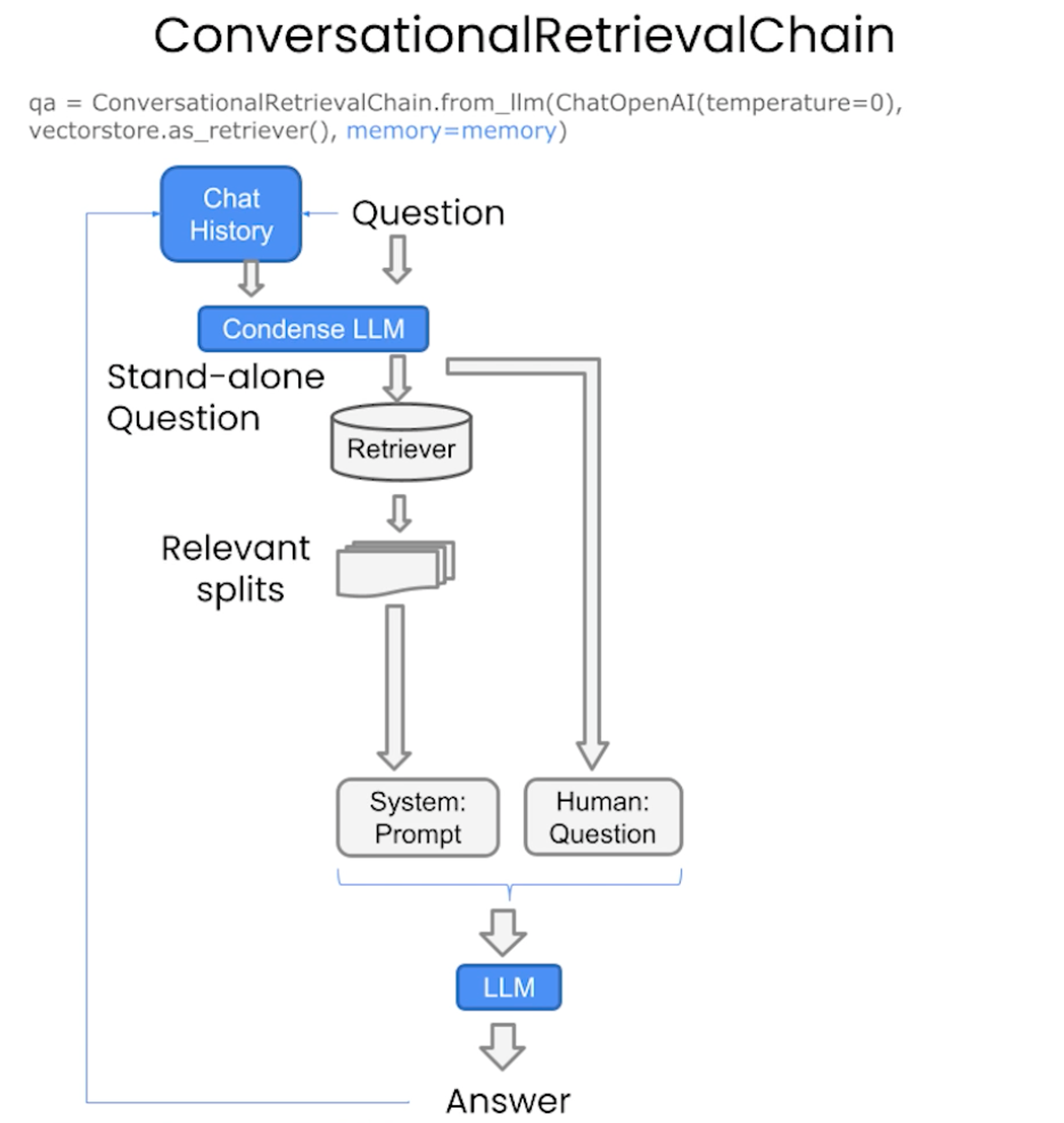
Chat
Notebook Code
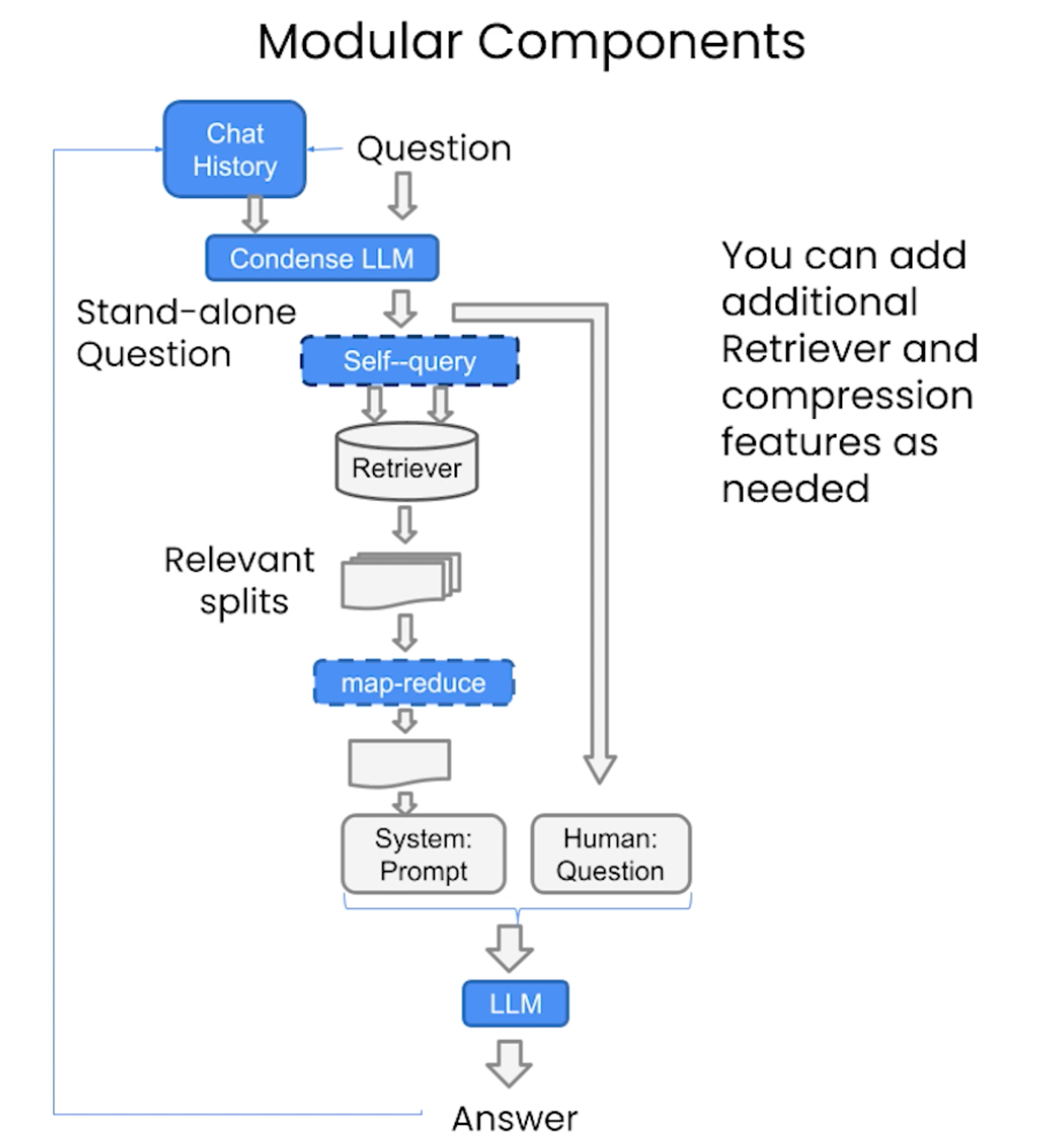
#!/usr/bin/env python # coding: utf-8 # # Chat # # Recall the overall workflow for retrieval augmented generation (RAG): #  # We discussed `Document Loading` and `Splitting` as well as `Storage` and `Retrieval`. # # We then showed how `Retrieval` can be used for output generation in Q+A using `RetrievalQA` chain. # In[ ]: import os import openai import sys sys.path.append('../..') import panel as pn # GUI pn.extension() from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file openai.api_key = os.environ['OPENAI_API_KEY'] # The code below was added to assign the openai LLM version filmed until it is deprecated, currently in Sept 2023. # LLM responses can often vary, but the responses may be significantly different when using a different model version. # In[ ]: import datetime current_date = datetime.datetime.now().date() if current_date < datetime.date(2023, 9, 2): llm_name = "gpt-3.5-turbo-0301" else: llm_name = "gpt-3.5-turbo" print(llm_name) # If you wish to experiment on `LangChain plus platform`: # # * Go to [langchain plus platform](https://www.langchain.plus/) and sign up # * Create an api key from your account's settings # * Use this api key in the code below # In[ ]: #import os #os.environ["LANGCHAIN_TRACING_V2"] = "true" #os.environ["LANGCHAIN_ENDPOINT"] = "https://api.langchain.plus" #os.environ["LANGCHAIN_API_KEY"] = "..." # In[ ]: from langchain.vectorstores import Chroma from langchain.embeddings.openai import OpenAIEmbeddings persist_directory = 'docs/chroma/' embedding = OpenAIEmbeddings() vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding) # In[ ]: question = "What are major topics for this class?" docs = vectordb.similarity_search(question,k=3) len(docs) # In[ ]: from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model_name=llm_name, temperature=0) llm.predict("Hello world!") # In[ ]: # Build prompt from langchain.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,) # Run chain from langchain.chains import RetrievalQA question = "Is probability a class topic?" qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectordb.as_retriever(), return_source_documents=True, chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}) result = qa_chain({"query": question}) result["result"] # ### Memory # In[ ]: from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory( memory_key="chat_history", return_messages=True ) # ### ConversationalRetrievalChain # In[ ]: from langchain.chains import ConversationalRetrievalChain retriever=vectordb.as_retriever() qa = ConversationalRetrievalChain.from_llm( llm, retriever=retriever, memory=memory ) # In[ ]: question = "Is probability a class topic?" result = qa({"question": question}) # In[ ]: result['answer'] # In[ ]: question = "why are those prerequesites needed?" result = qa({"question": question}) # In[ ]: result['answer'] # # Create a chatbot that works on your documents # In[ ]: from langchain.embeddings.openai import OpenAIEmbeddings from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter from langchain.vectorstores import DocArrayInMemorySearch from langchain.document_loaders import TextLoader from langchain.chains import RetrievalQA, ConversationalRetrievalChain from langchain.memory import ConversationBufferMemory from langchain.chat_models import ChatOpenAI from langchain.document_loaders import TextLoader from langchain.document_loaders import PyPDFLoader # The chatbot code has been updated a bit since filming. The GUI appearance also varies depending on the platform it is running on. # In[ ]: def load_db(file, chain_type, k): # load documents loader = PyPDFLoader(file) documents = loader.load() # split documents text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150) docs = text_splitter.split_documents(documents) # define embedding embeddings = OpenAIEmbeddings() # create vector database from data db = DocArrayInMemorySearch.from_documents(docs, embeddings) # define retriever retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k}) # create a chatbot chain. Memory is managed externally. qa = ConversationalRetrievalChain.from_llm( llm=ChatOpenAI(model_name=llm_name, temperature=0), chain_type=chain_type, retriever=retriever, return_source_documents=True, return_generated_question=True, ) return qa # In[ ]: import panel as pn import param class cbfs(param.Parameterized): chat_history = param.List([]) answer = param.String("") db_query = param.String("") db_response = param.List([]) def __init__(self, **params): super(cbfs, self).__init__( **params) self.panels = [] self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf" self.qa = load_db(self.loaded_file,"stuff", 4) def call_load_db(self, count): if count == 0 or file_input.value is None: # init or no file specified : return pn.pane.Markdown(f"Loaded File: {self.loaded_file}") else: file_input.save("temp.pdf") # local copy self.loaded_file = file_input.filename button_load.button_style="outline" self.qa = load_db("temp.pdf", "stuff", 4) button_load.button_style="solid" self.clr_history() return pn.pane.Markdown(f"Loaded File: {self.loaded_file}") def convchain(self, query): if not query: return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True) result = self.qa({"question": query, "chat_history": self.chat_history}) self.chat_history.extend([(query, result["answer"])]) self.db_query = result["generated_question"] self.db_response = result["source_documents"] self.answer = result['answer'] self.panels.extend([ pn.Row('User:', pn.pane.Markdown(query, width=600)), pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'})) ]) inp.value = '' #clears loading indicator when cleared return pn.WidgetBox(*self.panels,scroll=True) @param.depends('db_query ', ) def get_lquest(self): if not self.db_query : return pn.Column( pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})), pn.Row(pn.pane.Str("no DB accesses so far")) ) return pn.Column( pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})), pn.pane.Str(self.db_query ) ) @param.depends('db_response', ) def get_sources(self): if not self.db_response: return rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))] for doc in self.db_response: rlist.append(pn.Row(pn.pane.Str(doc))) return pn.WidgetBox(*rlist, width=600, scroll=True) @param.depends('convchain', 'clr_history') def get_chats(self): if not self.chat_history: return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True) rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))] for exchange in self.chat_history: rlist.append(pn.Row(pn.pane.Str(exchange))) return pn.WidgetBox(*rlist, width=600, scroll=True) def clr_history(self,count=0): self.chat_history = [] return # ### Create a chatbot # In[ ]: cb = cbfs() file_input = pn.widgets.FileInput(accept='.pdf') button_load = pn.widgets.Button(name="Load DB", button_type='primary') button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning') button_clearhistory.on_click(cb.clr_history) inp = pn.widgets.TextInput( placeholder='Enter text here…') bound_button_load = pn.bind(cb.call_load_db, button_load.param.clicks) conversation = pn.bind(cb.convchain, inp) jpg_pane = pn.pane.Image( './img/convchain.jpg') tab1 = pn.Column( pn.Row(inp), pn.layout.Divider(), pn.panel(conversation, loading_indicator=True, height=300), pn.layout.Divider(), ) tab2= pn.Column( pn.panel(cb.get_lquest), pn.layout.Divider(), pn.panel(cb.get_sources ), ) tab3= pn.Column( pn.panel(cb.get_chats), pn.layout.Divider(), ) tab4=pn.Column( pn.Row( file_input, button_load, bound_button_load), pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" )), pn.layout.Divider(), pn.Row(jpg_pane.clone(width=400)) ) dashboard = pn.Column( pn.Row(pn.pane.Markdown('# ChatWithYourData_Bot')), pn.Tabs(('Conversation', tab1), ('Database', tab2), ('Chat History', tab3),('Configure', tab4)) ) dashboard # Feel free to copy this code and modify it to add your own features. You can try alternate memory and retriever models by changing the configuration in `load_db` function and the `convchain` method. [Panel](https://panel.holoviz.org/) and [Param](https://param.holoviz.org/) have many useful features and widgets you can use to extend the GUI. # # ## Acknowledgments # # Panel based chatbot inspired by Sophia Yang, [github](https://github.com/sophiamyang/tutorials-LangChain)


⚠️Disclaimer: All the screenshots, materials, and other media documents used in this article are copyrighted to the original platform or authors.