

Important Links
LLM-Evaluation
rajshah4 • Updated Jan 22, 2024
Key Takeaways
Are Leaderboards useful?
Automated evaluation pipelines are better.

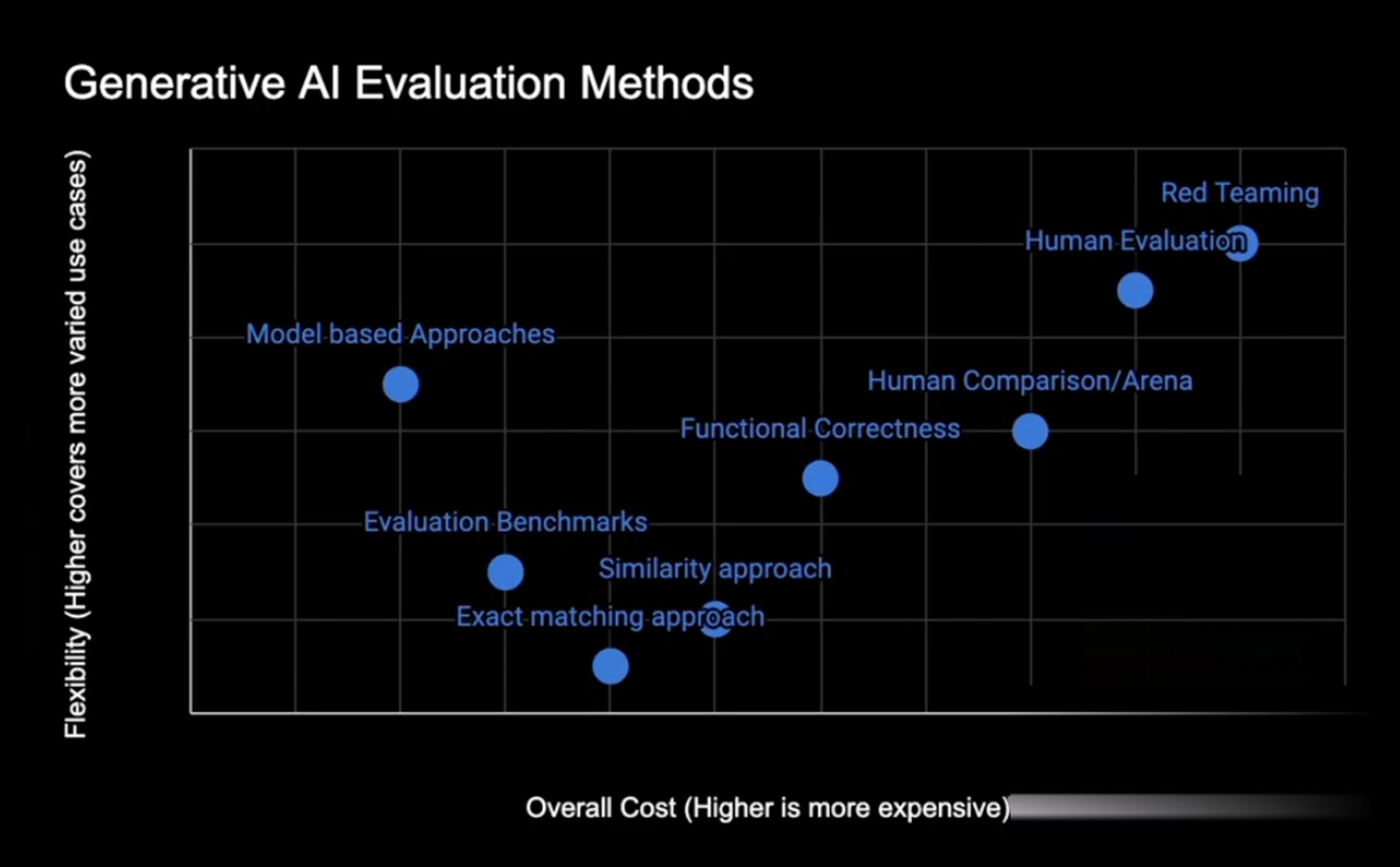
Methods for evaluation
- Exact matching approach
- Prompts are highly sensitive to characters like bracket or space
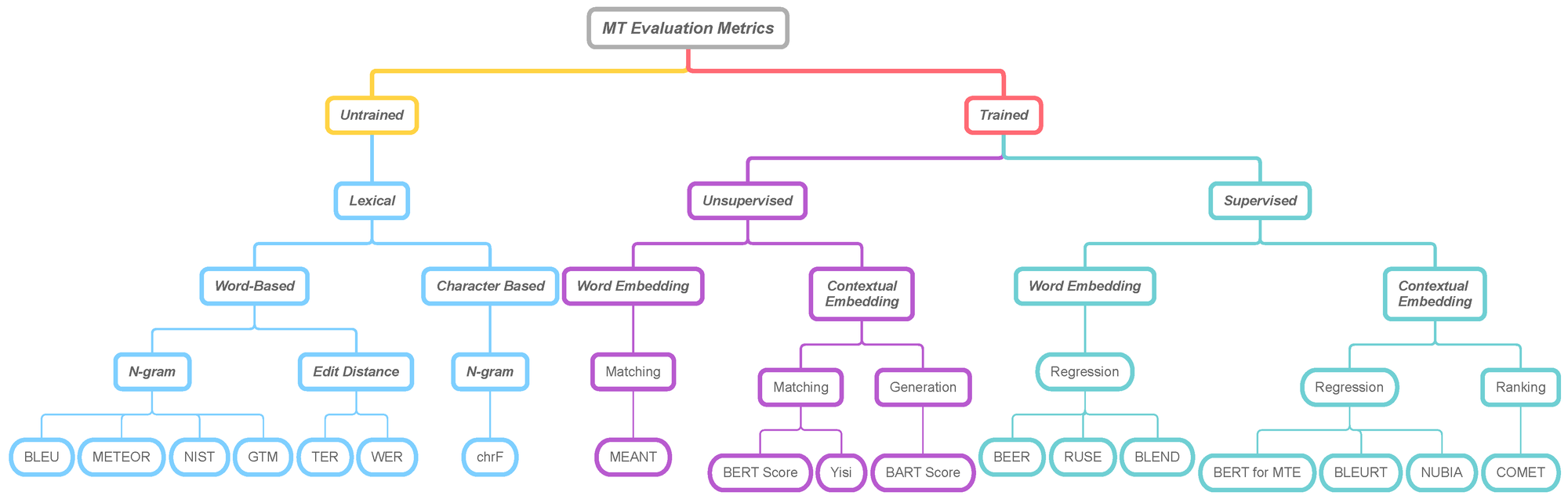
- Similarity approach
- Types:
- BLEU score
- Exact match
- Edit distance
- ROUGE scores
- Word Error Rate
- METEOR
- Cosine similarity
- Pros:
- Fast
- Easy
- Cons:
- Biased towards shorter text → Gives better result there.
- Does not consider meaning and sentence structure
- Tokenization redundant

- Functional Correctness Evaluation
- Benchmarks
- GLUE
- BigBench
- List of commonly used benchmarks for LLMs — LessWrong
- Pros:
- A wide range of tasks can be evaluated
- cheap and easy
- Cons:
- Good for MCQs, not for free form texts
- Leakage of training on test data
- Human Evaluation
- Pros:
- Humans can evaluate a WIDE variety of outputs
- Humans are the gold standard for some benchmarks
- Cons:
- Humans are expensive
- Humans are large variation (mood and emotions)
- Can be biased and low factuality
- Can be manipulated by different prompts
- Human Comparison/Arena
- Model based Approaches
- gEval
- SelfCheckGPT
- JudgeLM → Write a model to evaluate another model
- Ragas
- Red Teaming
Consistent output can be made sure with:
- OpenAI function calling &
- Microsoft guardrailing
Evaluation Components
Retrieval:
- Low Precision: Not all chunks in retrieved set are relevant
- Low Recall: Not all relevant chunks are retrieved.
- Were they in the proper order?
- Were they outdated
- What was the latency?
Augmentation:
- How can we ensure the answer were factually correct?
- How can we measure the answers were understandable?
- Toxicity/Bias issues
- How can we measure latency
⚠️Disclaimer: All the screenshots, materials, and other media documents used in this article are copyrighted to the original platform or authors.