

Important Links
auto-evaluator
rlancemartin • Updated Jan 22, 2024
Key Takeaways
Common types of LLM mistakes
- Hallucination (confidently stating something incorrect)
- Bad output formatting
- Wrong tone
- Provoked to go "off the rails"
- Overly cautious ("RLHF responses")
- Repetitions
How Evaluation helps
- Validation that your model avoids common failures modes
- Common language to make fast go / no-go decisions
- Roadmap for improvements to model performance
What makes a good evaluation
- Correlated with outcomes
- A single metric (or a small number of metrics)
- Fast & automatic to compute
LLM Evaluation
- We do not have access to training data of LLMs.
- Prod distribution is always different than training
- Trained on the internet there is always drift, it doesn't matter as much
- Qualitative A Hard-to-measure success
- Diversity of behaviors aggregate metrics don't work

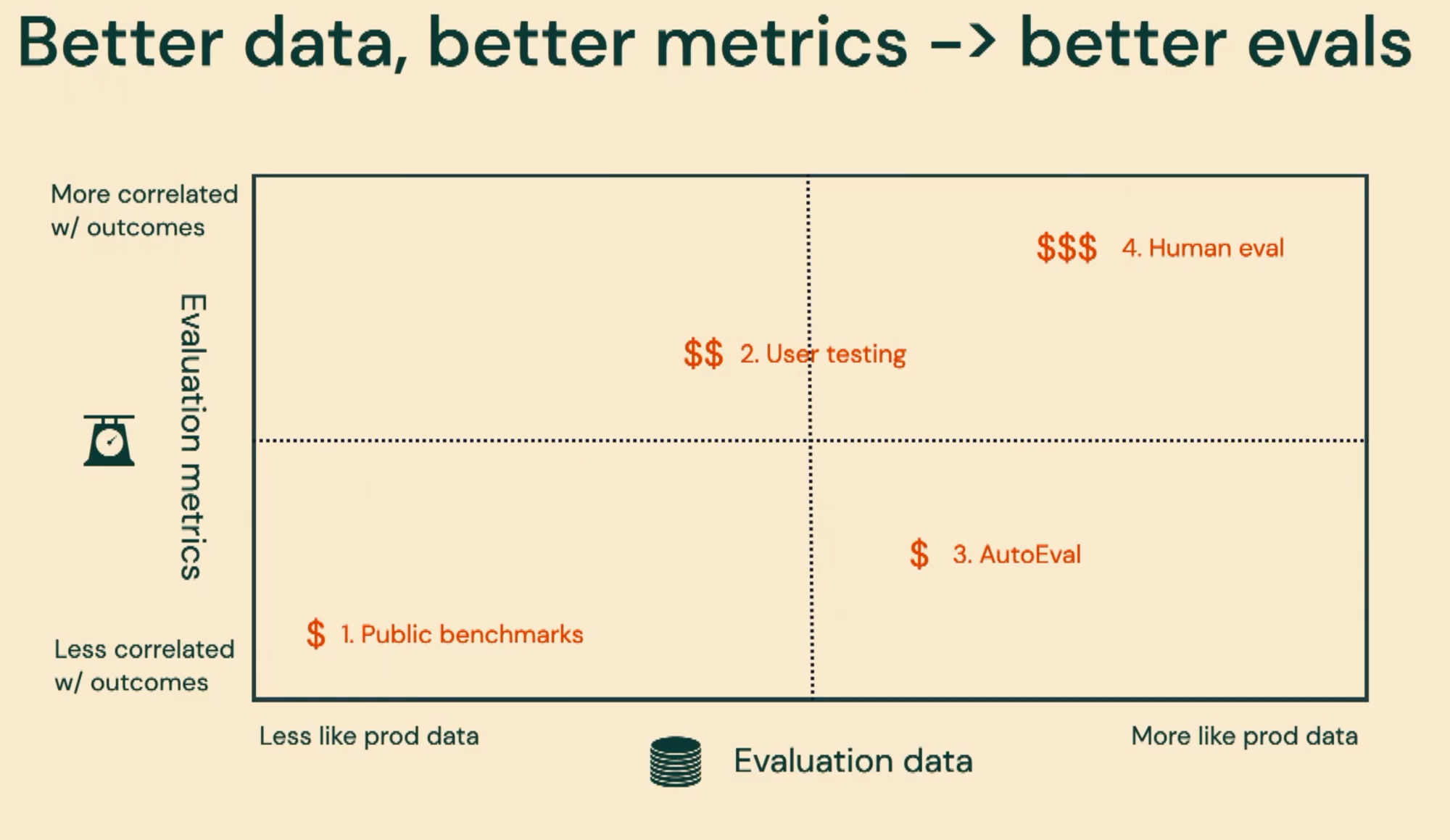
What's wrong with benchmarks
- Benchmarks don't measure performance on your use case
- They don't take into account your prompting, your in-context learning, your fine-tuning, etc
- They also have all of the measurement issues we're talking about
Solution
- Use LLM to create your own evaluation dataset.
- Do incrementally and increase the coverage
- Make reliable evaluation metrics
Evaluation metrics for LLMs


- Regular eval metrics
- Accuracy, etc
- Reference matching metrics
- Semantic similarity
- Ask another LLM, "are these two answers factually consistent" etc
- "Which is better" metrics
- Ask an LLM which of the two answers is better, according to any criteria you want
- "Is the feedback incorporated" metrics
- Ask an LLM whether the new answer incorporates the feedback on the old answer
- Static metrics
- Verify the output has the right structure (e.g., is JSON formatted)
- Ask a model to grade the answer (on a scale of 1 to 5)
⚠️Disclaimer: All the screenshots, materials, and other media documents used in this article are copyrighted to the original platform or authors.