With the rise of LLMs it has become difficult for human judges to evaluate the quality of LLMs. In the products where we use LLMs, usually we do not use evals. However, even if we use evals the default choice we set as LLM-as-a-judge based evals with a costly model.
Large Language Models (LLMs) are increasingly being used as judges or evaluators for various tasks, offering a promising alternative to traditional human evaluation due to their scalability, near real time evaluation and potential cost-effectiveness. They act as evaluative tools leveraging their extensive knowledge and deep contextual understanding. At its core, this means using the LLM’s probability function to process input data along with context, such as prompt templates, to generate an evaluation output, which could be a score, a choice, a label, or text.
However, just as human judges can have limitations, LLMs used as judges also face challenges and exhibit patterns of failures. This raises a critical question: Who will judge the judge? To rely more on LLMs as judges, we need to rigorously examine their weaknesses and develop strategies to improve their performance and reliability.
Here, we’ll look at some common problems I have encountered when using LLMs as judges and how we can address them.
Problem: Reliability Issues (Consistency & Fairness)
Ensuring the reliability of LLM-as-a-Judge systems is a significant challenge that requires careful design and standardization. LLMs are probabilistic models, and merely employing them does not guarantee accurate evaluations aligned with established standards.
LLM evaluations can be inconsistent and unfair. This is partly because they are probabilistic models. Just like humans, they can exhibit biases. Ensuring robust and consistent outputs from LLMs trained with techniques like Reinforcement Learning from Human Feedback (RLHF) remains challenging.
Solution: Reliability Enhancement Strategies
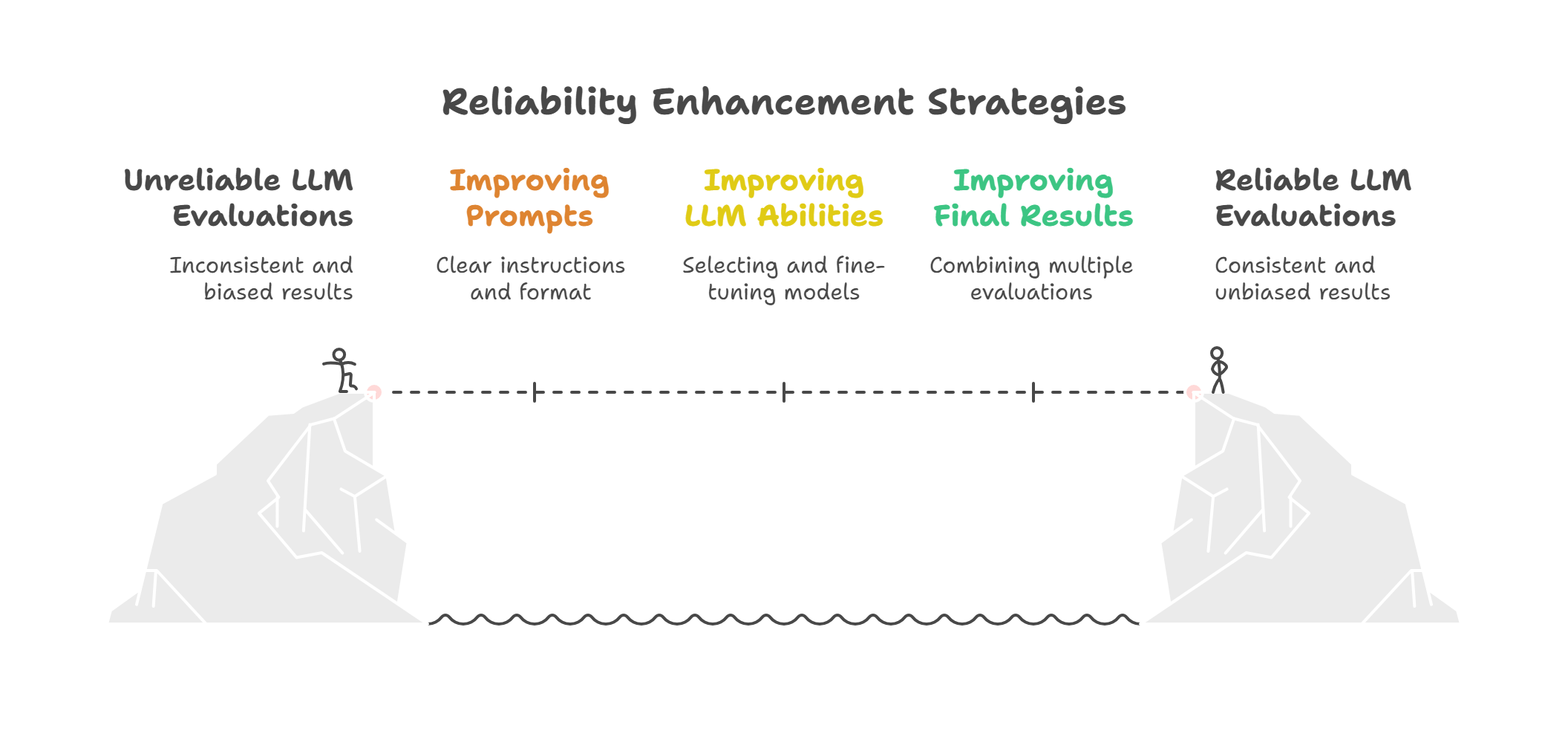

Strategies to enhance reliability include improving the evaluation prompts, enhancing the LLMs’ inherent abilities, and optimizing final results through post-processing.
- Improving Prompts (In-Context Learning Based): Designing effective prompts is crucial. This involves specifying scoring dimensions, emphasizing relative comparisons (which can improve assessments), and providing effective examples to guide the LLM. Constraining or guiding the output format, such as using structured formats like JSON, specific numerical scores, or binary responses, can improve robustness and facilitate automated post-processing.
- Improving LLMs’ Abilities (Model Based): The effectiveness is linked to the base LLM’s instruction-following and reasoning capabilities. Selecting powerful, large-scale models with strong abilities is recommended. Refining the evaluation capabilities of LLMs through fine-tuning on meta-evaluation datasets is also significant.
- Improving Final Results (Post-processing Based): Combining results from multiple evaluations can enhance reliability. This can involve:
- Multiple Rounds: Evaluating content multiple times and integrating the results. Taking the majority vote from repeated evaluations shows benefits in reducing the impact of randomness and addressing biases. However, averaging or taking the best score from multiple rounds may not be as effective. Obviously, this will be more expensive.
- Multiple LLMs: Using multiple different LLM evaluators simultaneously and integrating their results (e.g., by voting) can reduce biases introduced by individual LLMs. One Azure/AWS Bedrock cloud based LLM and one self-hosted open source LLM can be deployed as judges.
Problem: Persistent Biases
LLM evaluators can inherit and exhibit various types of biases present in their training data or introduced by the evaluation setup. These biases undermine fairness and reliability. Common biases include:
- Presentation-Related Biases:
- Position Bias: Favoring responses based on their order of presentation.
- Verbosity Bias: Favoring longer responses over shorter ones, even if content quality is similar.
- Content-Related Biases:
- Concreteness Bias: Favoring responses with specific details, including citation of authoritative sources (also called authority bias or citation bias), potentially neglecting factual correctness.
- Bandwagon-Effect Bias: Aligning judgments with majority opinion or prevailing trends.
- Self-enhancement Bias: Favoring the model’s own generated outputs over others.
- Distraction Bias: Being influenced by irrelevant or unimportant details.
- Evaluation Biases:
- Overconfidence Bias: Overstating the correctness of certain outputs.
- Refinement-aware Bias: Potentially being influenced by internal iterations or self-perception during judgment.
Solution: Mitigating Biases
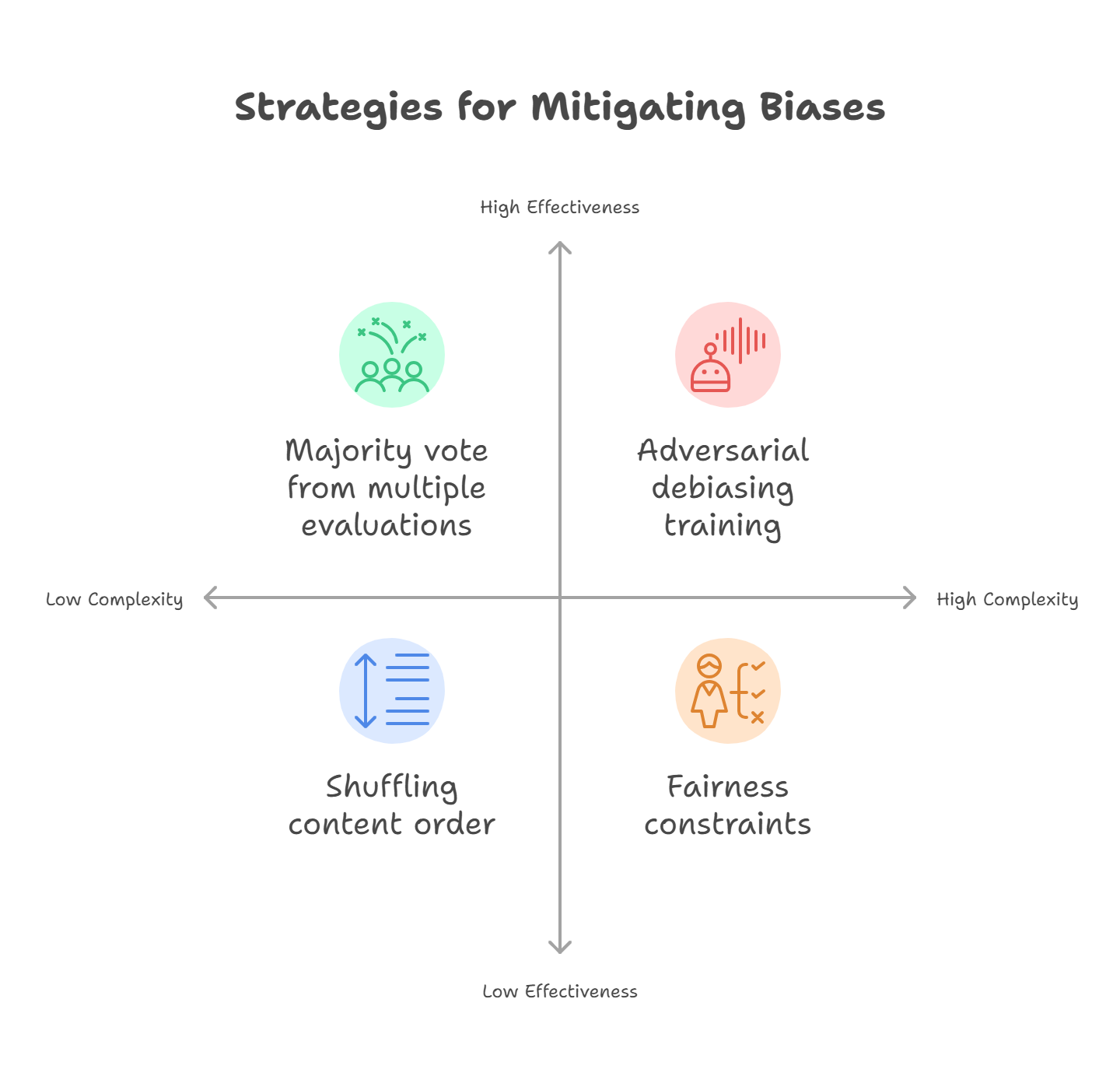
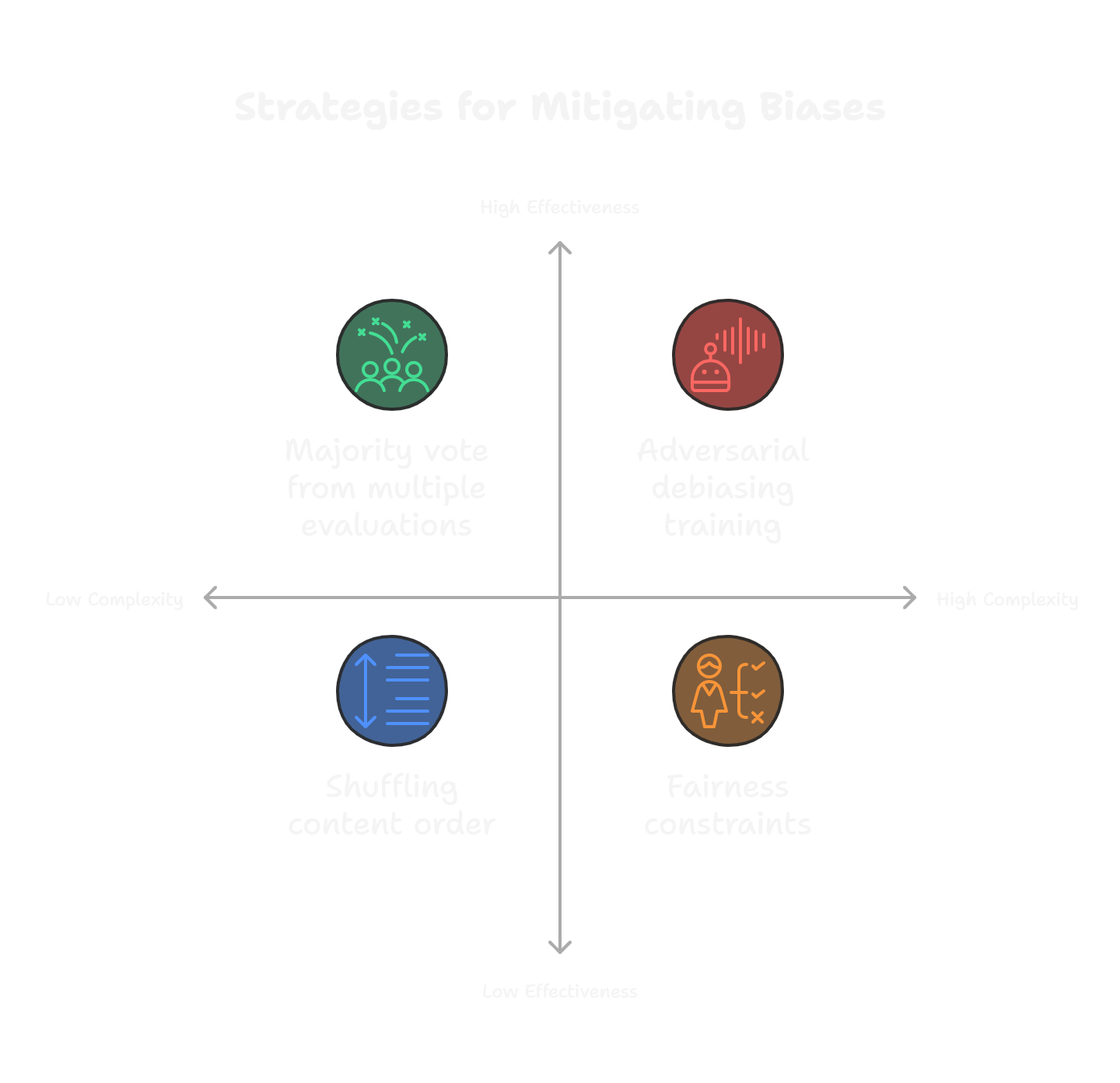
Mitigating these inherent biases is a critical challenge.
- Prompting Strategies: Techniques like shuffling the order of content being evaluated can help mitigate position bias. Explicitly emphasizing semantic accuracy and relevance over perceived authority in prompts might help with concreteness bias.
- Post-processing Strategies: Taking the majority vote from multiple evaluation rounds (as mentioned under reliability) can help address bias issues.
- Advanced Techniques: Potential approaches include using debiasing algorithms and fairness constraints. Adversarial debiasing training or bias detection tools can dynamically identify and mitigate biases. Integrating external feedback mechanisms during judgment can introduce objectivity.
Problem: Opaque Decisions (Lack of Interpretability and Transparency)
Often, the decision-making process of LLM-as-a-Judge systems is like a black box, lacking transparency and clear reasoning steps. This makes it difficult for users to understand or trust the basis of the judgment, which is particularly problematic in high-stakes domains like legal cases.
Solution: Improving Transparency and Explanations
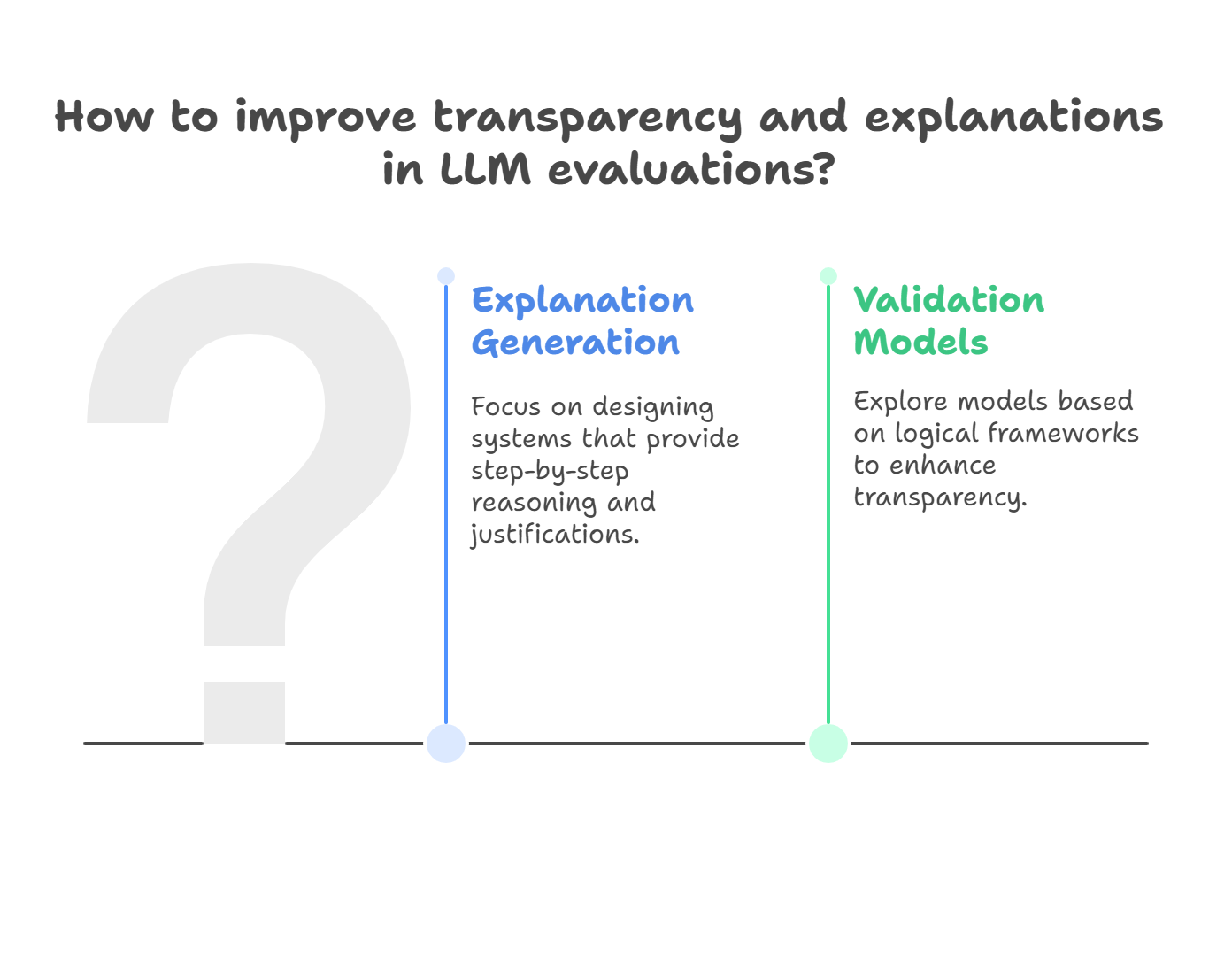
- LLM judges should not only provide evaluation results but also present clear explanations and justifications.
- Explanation Generation: Focus on designing systems where the LLM provides step-by-step reasoning, justifications, or decision-making insights.
- Validation Models: Explore validation models based on logical frameworks to make the decision process more transparent.
Problem: Dependence on Backbone Model Quality
The effectiveness of LLM-as-a-Judge is significantly affected by the limitations of the base LLM used if it lacks strong instruction-following or reasoning abilities. Smaller and more cost-efficient models have been found to be less effective judges compared to the best available, larger LLMs.
Solution: Model Selection and Fine-tuning
- Choose Powerful Models: It is recommended to select large-scale models with strong reasoning and instruction-following abilities for reliable evaluations. State-of-the-art LLMs like GPT-4 Turbo and Llama-3 70B have shown higher alignment with human judgments compared to smaller models.
- Fine-tune for Evaluation: Refine LLMs tailored for evaluations by emphasizing approaches like pairwise comparisons or grading, using data annotated by powerful models, can create more scalable evaluators. Iteratively optimizing models based on evaluation feedback is also significant.
Problem: Alignment Challenges with Human Judgment
Aligning LLM judgments with human preferences is a common evaluation approach. However, even well-aligned LLMs can sometimes deviate from human scores. Furthermore, commonly used metrics like simple percent aligned may not fully capture the nuances or reliably discriminate between different judges. LLMs as judges do not always satisfy properties like transitivity in preferences, contributing to concerns about trustworthiness.
Solution: Better Metrics and Human Oversight
- Use Robust Metrics: In addition to percent agreement, using more robust metrics like Scott’s π is recommended, as it can distinguish judges better.
- Combine Quantitative and Qualitative Analysis: Pair quantitative results with qualitative analysis to ensure valid conclusions from LLM judges.
- Human-in-the-Loop: Implement human oversight, especially for critical decisions, to ensure alignment with societal values and professional standards.
- Develop Benchmarks: Creating comprehensive evaluation benchmarks is crucial for assessing and improving reliability. Benchmarks should reflect objective correctness.
Summary and more
Cost vs Accuracy
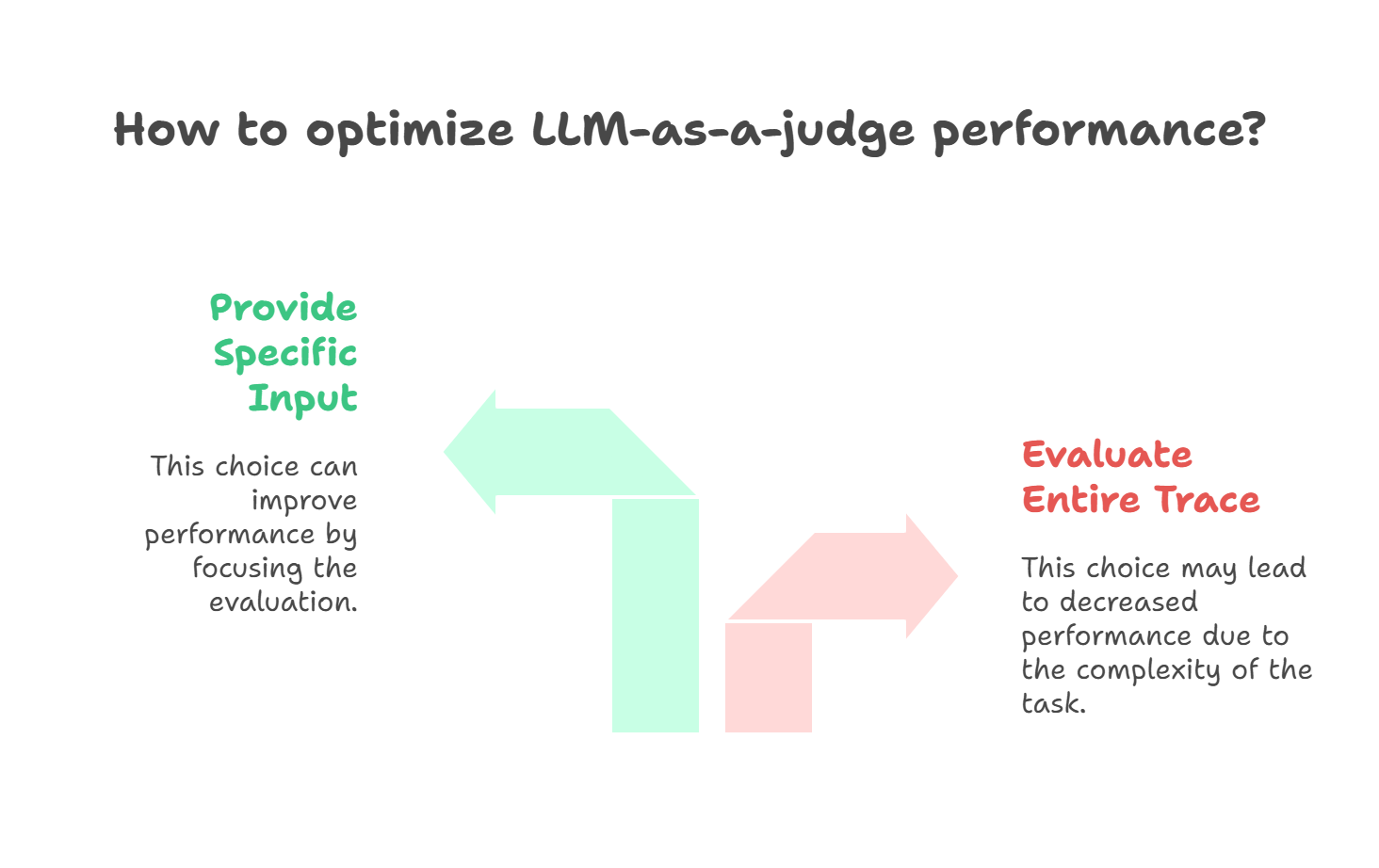
- You may have asked your judge to evaluate the entire trace or conversation with different kinds of evals.
- This will drastically decreases the performance of your LLM-as-a-judge.
- Give specific input to your judge and expect a certain eval score.
Are you using your evals?

- Vendors come up with generic eval scores like hallucination, toxicity, coherence, etc. but these are not always relevant to your application context.
- It is important to validate the evals being used.
- Are these evals set the right metrics for your application context? Does it matter if these score is high or low? Are you simply burning your budget by running these evals?
- If the evals matter to you, do you need to run these in every response of the LLMs? Do you want to take a sample and run these evals to reduce your token usage?
Generic Evals are useless
- To ask whether the tone is appropriate to a judge and not providing the context is a sin.
- Your use case is unique and the generic evals do not capture that. Tune your prompts or provide the context to your judge.
- For e.g. the tone of a chatbot for a restaurant can be different from a chatbot for a bank.
- Use few shot prompting by providing examples to your judge. This examples also need to be fetched from use case specific data.
Ask for justification
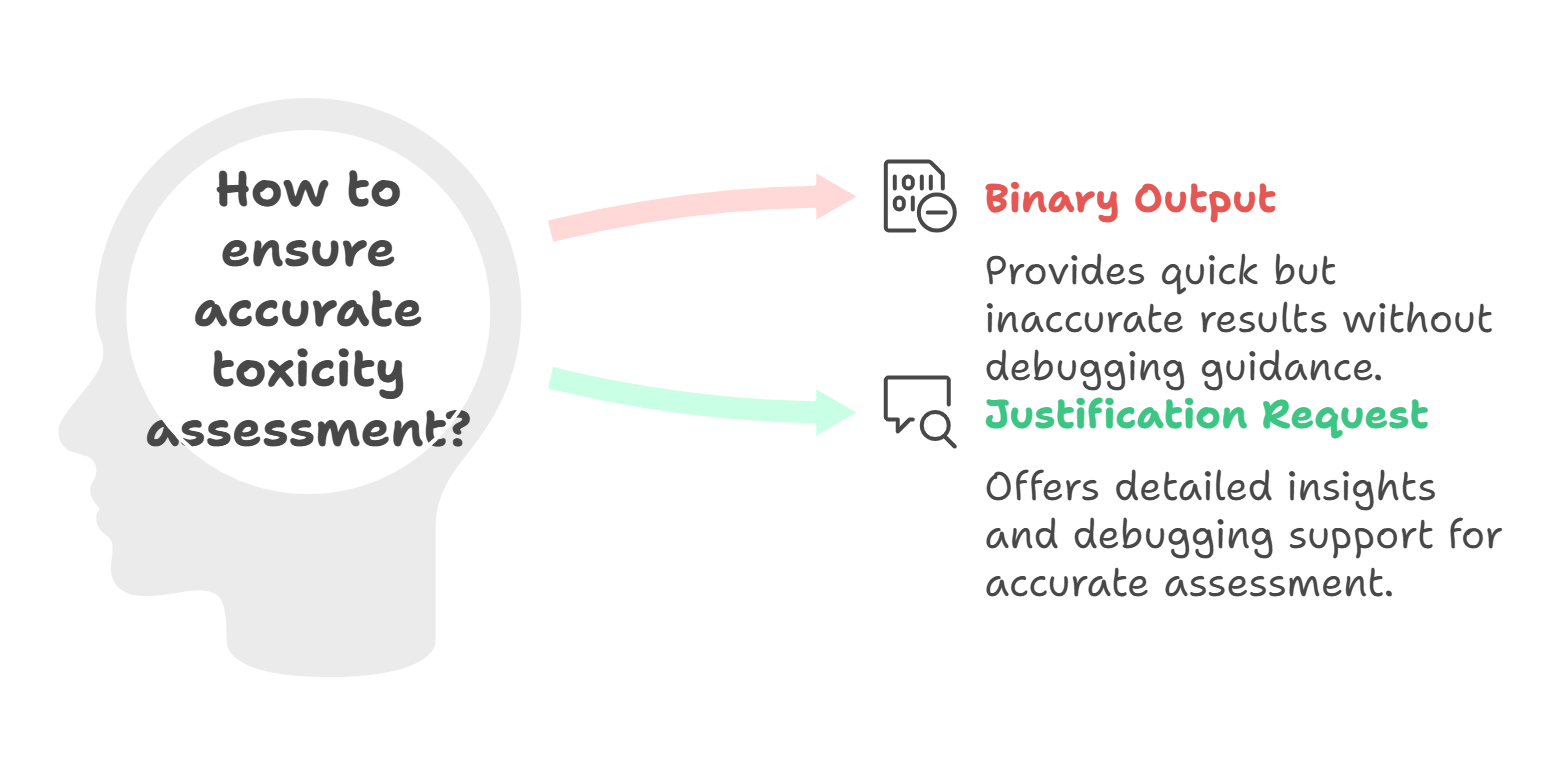

- Simply asking binary output from your judge like Respond if the response is toxic mostly will not provide accurate response.
- In addition to that it will not help the users on how to debug further if a response is toxic.
- Ask for justification on why the response is toxic.
Are the prompts being followed?
- LLM-as-a-judge does not always follow the instructions given to it. It is important to validate the prompts being followed.
- The contexts (variable parameters, conversation history, etc.) you have provided to the LLM-as-a-judge should be validated.
Output should be binary if not multi class classification
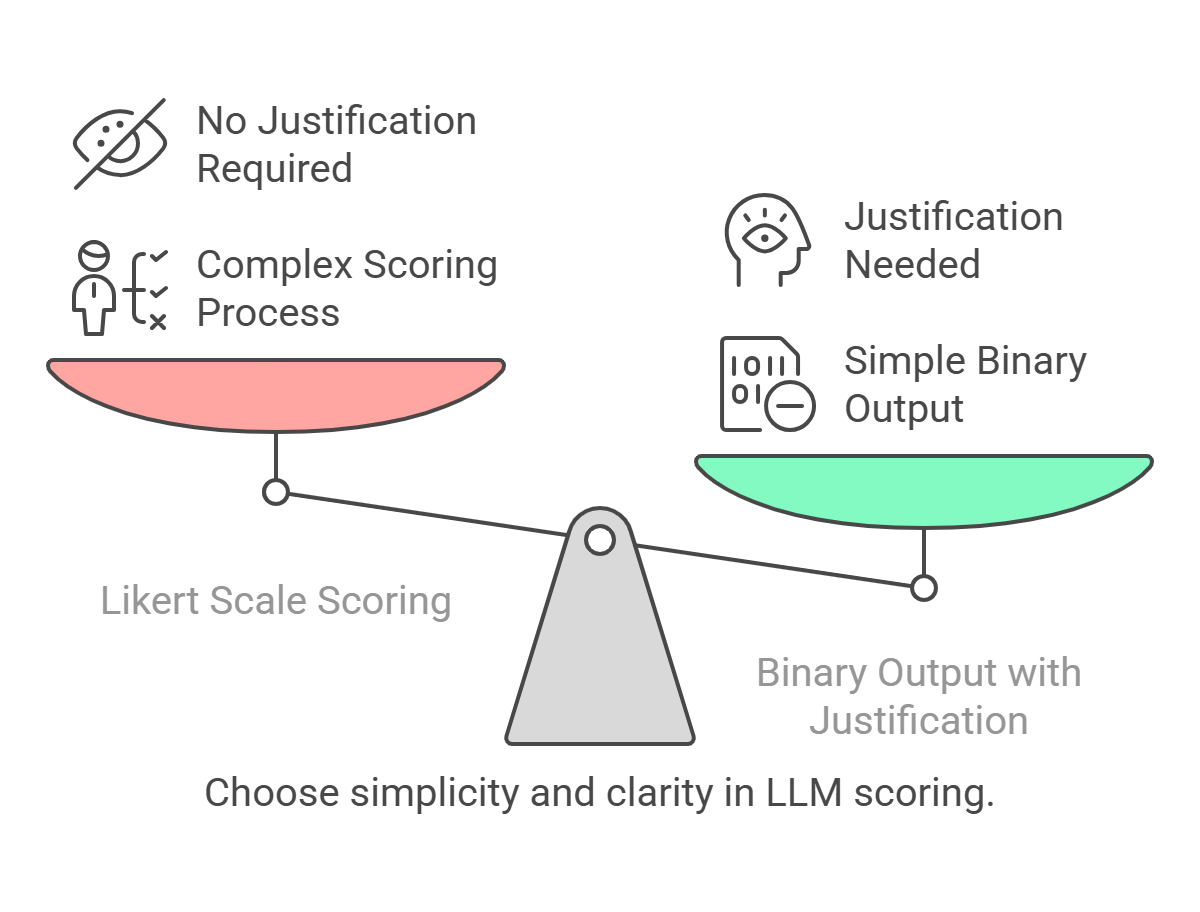
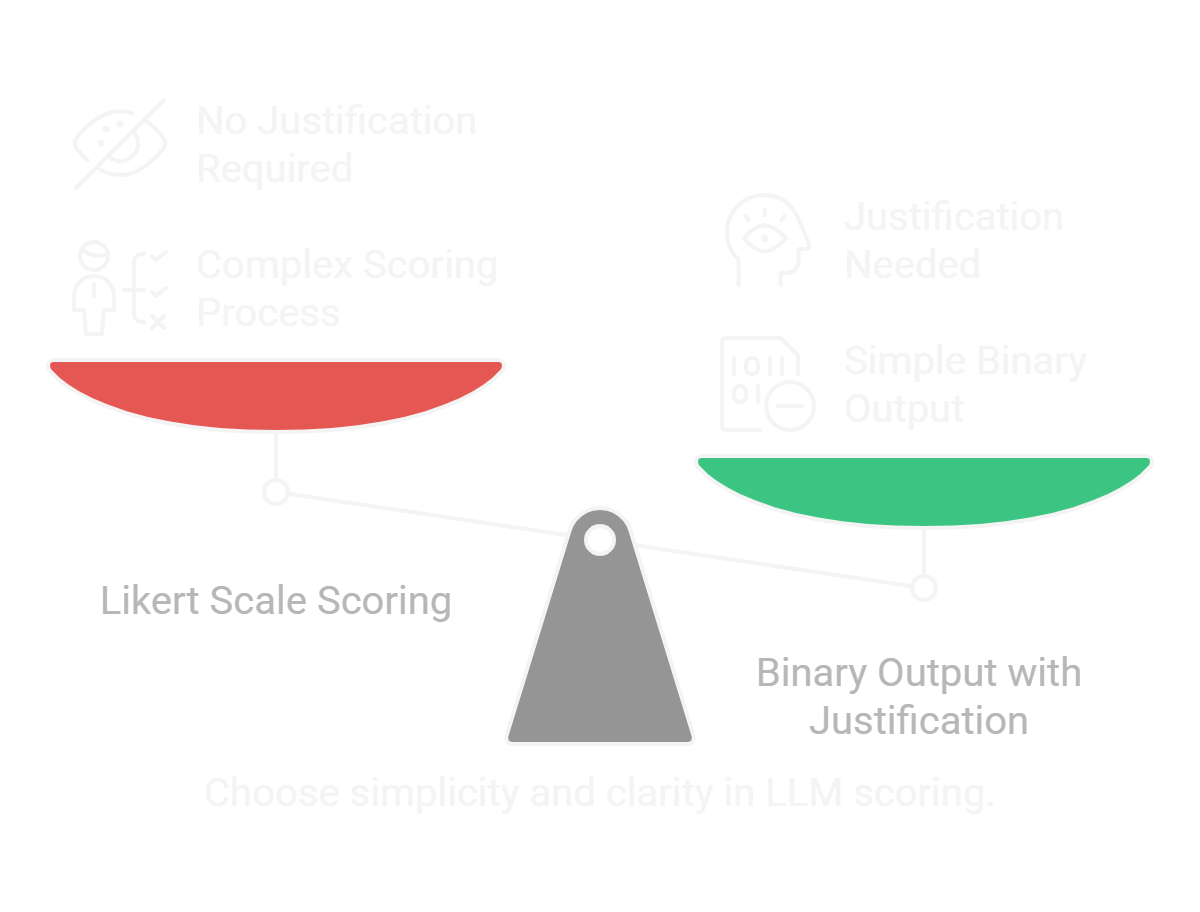
- It is difficult for the judge to provide a score from 1 to 5 like likert scale.
- It is better to provide binary output and justify the output.
- To not provide examples on what does each score mean is a blunder.This requires more effort and can be a waste of time.
- It is better to ask for binary output and justify the output. For e.g. reply in
Yes or No format with justification.
Don’t blindly take decisions based on LLM benchmarks
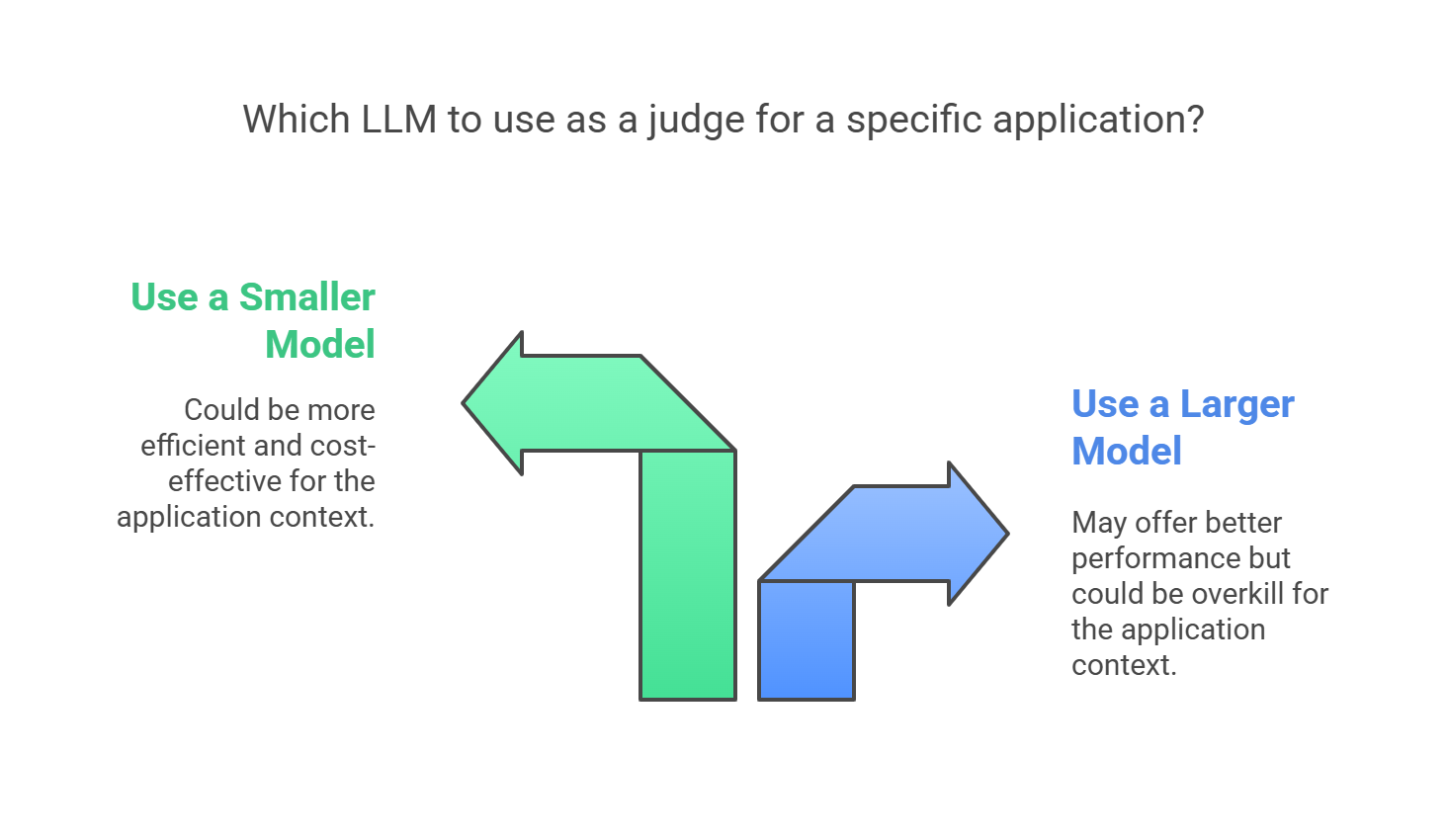

- Foundational LLM benchmark does not necessarily reflect the performance of LLMs as judges in your application customized for a specific need like say a chatbot on your FAQ data.
- A smaller model may perform better as a judge than a larger model on your application context.
- Sometimes less is more.
- Always validate your LLMs as judges on your application context. May be a smaller and cheaper model can perform on an expected level.
Sampling and Human Evaluation
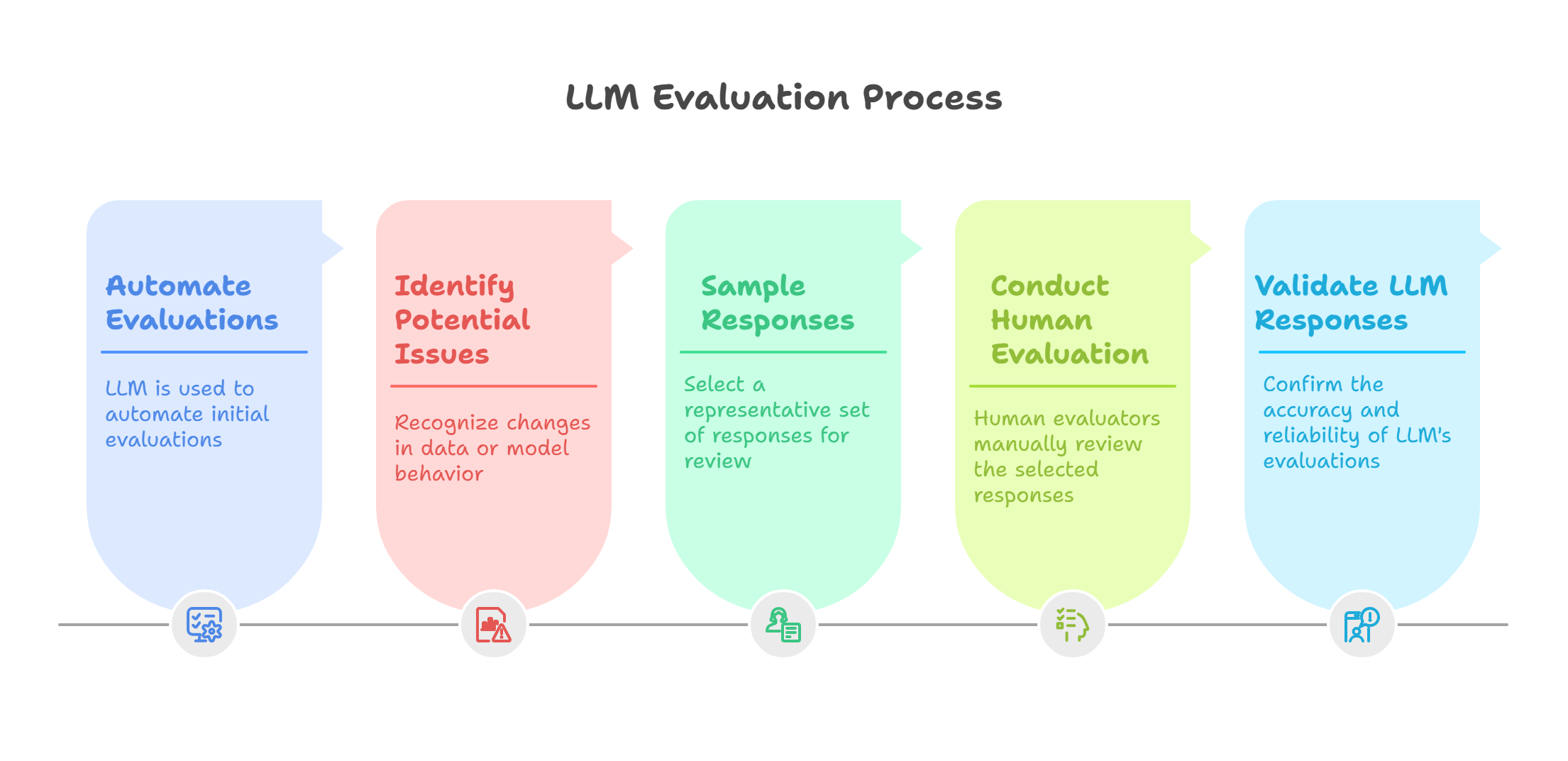
- Automating the evals via LLM as a judge does not mean we can completely skip the human evaluation.
- The user inputs may get change, production data may get drifted, the model responses may get biased, or out of date.
- The LLM-as-a-judge responses need to be validated by human evaluator.
- Take sample of each type of your responses and validate manually in a specific frequency.
Conclusion
LLM-as-a-Judge systems offer significant potential for scalable and adaptable evaluation across diverse domains. However, achieving truly reliable, fair, and transparent judgments requires addressing inherent challenges related to biases, robustness, interpretability, and fundamental model capabilities. By implementing strategies focused on improving prompts, selecting and fine-tuning models, employing sophisticated post-processing techniques, utilizing robust evaluation metrics, and maintaining appropriate human oversight, we can move towards developing LLM judges that are more accurate, fair, and dependable assessment partners. While they may never be perfect, continuous research and practical application of these improvement strategies are essential for building trust and expanding the effective use of LLM-as-a-Judge systems.
References
Related Articles