How Retrieval-Augmented Generation is transforming from simple similarity matching to sophisticated knowledge graphs
Components of an RAG System
RAG combines information retrieval with text generation, allowing AI systems to access and leverage external knowledge before generating responses.
It works by first retrieving relevant documents or information from a knowledge base, then using this retrieved context to augment the AI’s generation process
Naive RAG
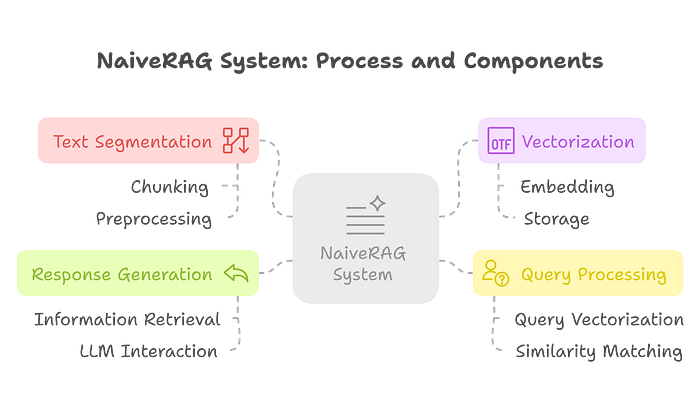
Naive RAG is presented as a standard baseline RAG system. It operates by first segmenting the raw text data into smaller chunks. These chunks are then converted into vectorized representations (embeddings) and stored in a vector database.
When a user poses a query, Naive RAG generates a vector representation of the query and retrieves the text chunks from the vector database that have the highest similarity to the query vector.
This retrieved information is then used by LLM to generate a response. Naive RAG relies on flat data representations and direct similarity matching of text chunks.
RQ-RAG
Refine Queries RAG
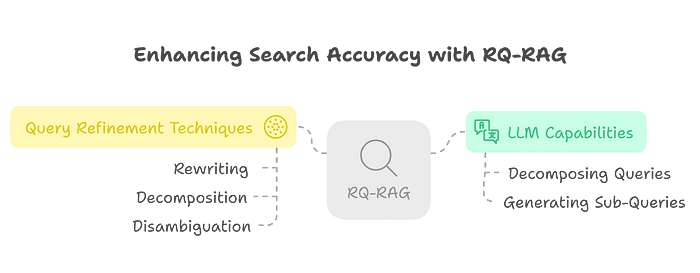
RQ-RAG (Learning to Refine Queries for Retrieval Augmented Generation) approach focuses on improving the search accuracy by refining the initial user query.
RQ-RAG utilizes the capabilities of an LLM to decompose the original query into multiple sub-queries. These sub-queries are designed to be more explicit and leverage techniques like rewriting, decomposition, and disambiguation to better target relevant information in the external knowledge source.
HyDE RAG
HyDE based RAG
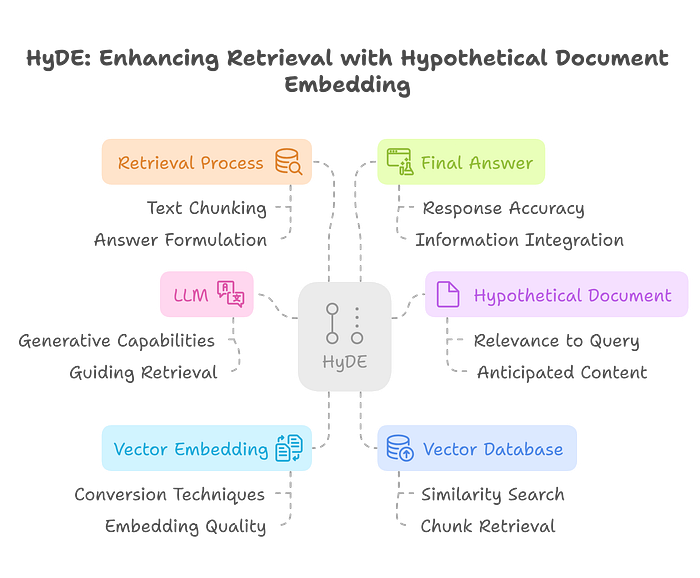
In HyDE (Hypothetical Document Embedding) approach, unlike direct retrieval based on query embeddings, an LLM is employed to first generate a hypothetical document that anticipates the would be relevant response to the input query.
This hypothetical document is then converted into a vector embedding, which is used to retrieve semantically similar text chunks from the vector database.
The retrieved chunks are subsequently used by the LLM to formulate the final answer. HyDE leverages the LLM’s generative capabilities to guide the retrieval process.
Graph RAG
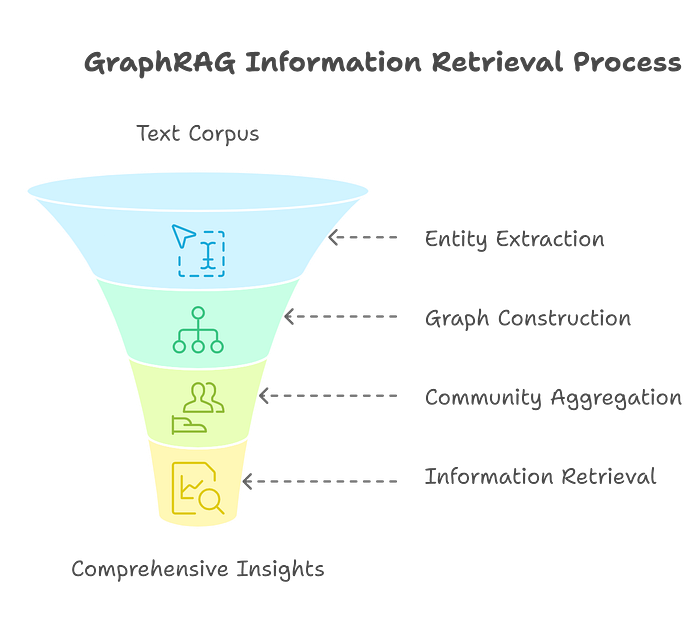
GraphRAG introduces a graph-based approach to knowledge representation and retrieval.
GraphRAG uses an LLM to extract entities and relationships from the text corpus, representing them as nodes and edges in a knowledge graph. It also generates descriptions for these graph elements.
To capture global information, GraphRAG aggregates nodes into communities and produces community reports.
When handling complex, high-level queries, GraphRAG retrieves information by traversing these communities in the knowledge graph, aiming to gather more comprehensive and interconnected information compared to chunk-based methods.
GraphRAG focuses on capturing relationships between entities for a more holistic understanding of the data.
Summary
Difference between various RAGs
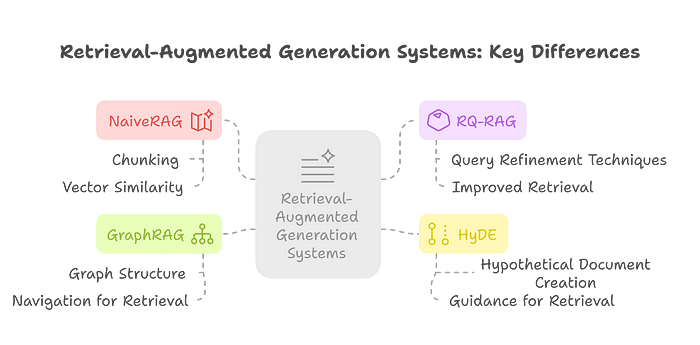
The key differences lie in how each system handles the external knowledge and the query:
NaiveRAG uses a simple chunking and vector similarity approach.
RQ-RAG refines the query itself to improve retrieval.
HyDE generates a hypothetical document to guide retrieval.
GraphRAG structures the knowledge as a graph and performs retrieval by navigating this structure.
Enters LightRAG
Advantages of LightRAG
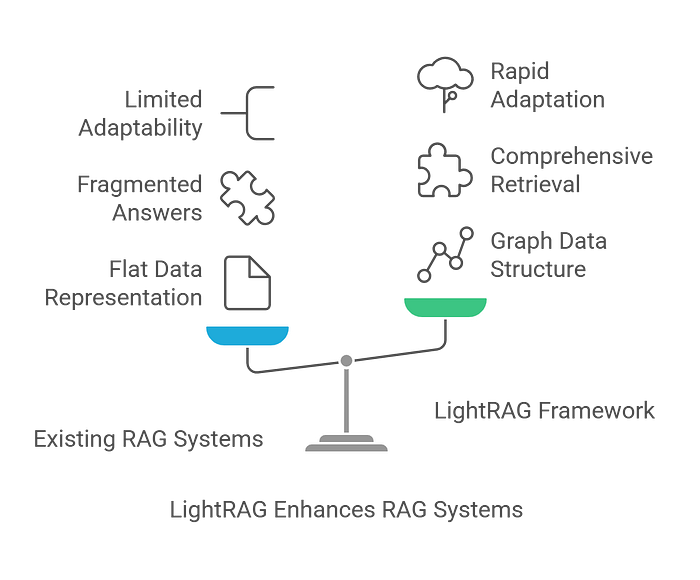
The LightRAG framework aims to improve upon these existing methods, particularly by addressing the limitations of flat data representations in systems like NaiveRAG and the potential for fragmented answers due to inadequate contextual awareness in many existing RAG systems.
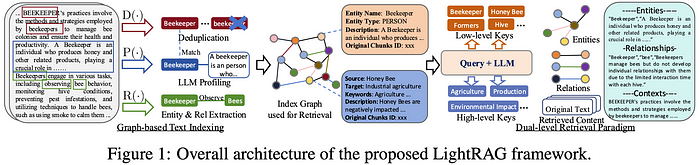
LightRAG incorporates graph structures into text indexing and retrieval and uses a dual-level retrieval system to enhance comprehensive information retrieval.
It also focuses on efficient retrieval and rapid adaptation to new data, which are highlighted as crucial aspects not fully addressed before.